How to use Queue: A beginner’s guide
Prerequisites
To learn about the Queue data structure, you should first have a good understanding of the following:
- Python 3
- Basic data structure concepts like List (Click here to refresh List concepts)
- OOP concepts
Introduction
This tutorial will help you understand a Queue data structure and how to implement it. These concepts are often tested in interviews and have a wide variety of applications. Python implementation of Queue is relatively simple when compared to other languages. Here you will learn how to do it in the Pythonic way and in a language agnostic way.
How to use Queue
A Queue is a simple data structure concept that can be easily applied in our day to day life, like when you stand in a line to buy coffee at Starbucks. Let’s make a few observations based on this example:
- People enter the line from one end and leave at the other end
- The person to arrive first leaves first and the person to arrive last leaves last
- Once all the people are served, there are none left waiting to leave the line
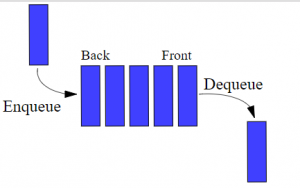
Now, let’s look at the above points programmatically:
- Queues are open from both ends meaning elements are added from the back and removed from the front
- The element to be added first is removed first (First In First Out – FIFO)
- If all the elements are removed, then the queue is empty and if you try to remove elements from an empty queue, a warning or an error message is thrown.
- If the queue is full and you add more elements to the queue, a warning or error message must be thrown.
Things to remember:
- The point of entry and exit are different in a Queue.
- Enqueue – Adding an element to a Queue
- Dequeue – Removing an element from a Queue
- Random access is not allowed – you cannot add or remove an element from the middle.
Implementation
We are going to see three different implementations. One is using Lists, another is using the library deque and the last is by using an array. Let’s take a look one by one…
Queue implementation using List
Here we are going to define a class Queue and add methods to perform the below operations:
- Enqueue elements to the beginning of the Queue and issue a warning if it’s full
- Dequeue elements from the end of the Queue and issue a warning if it’s empty
- Assess the size of the Queue
- Print all the elements of the Queue
class Queue:
#Constructor creates a list
def __init__(self):
self.queue = list()
#Adding elements to queue
def enqueue(self,data):
#Checking to avoid duplicate entry (not mandatory)
if data not in self.queue:
self.queue.insert(0,data)
return True
return False
#Removing the last element from the queue
def dequeue(self):
if len(self.queue)>0:
return self.queue.pop()
return ("Queue Empty!")
#Getting the size of the queue
def size(self):
return len(self.queue)
#printing the elements of the queue
def printQueue(self):
return self.queue
myQueue = Queue()
print(myQueue.enqueue(5)) #prints True
print(myQueue.enqueue(6)) #prints True
print(myQueue.enqueue(9)) #prints True
print(myQueue.enqueue(5)) #prints False
print(myQueue.enqueue(3)) #prints True
print(myQueue.size()) #prints 4
print(myQueue.dequeue()) #prints 5
print(myQueue.dequeue()) #prints 6
print(myQueue.dequeue()) #prints 9
print(myQueue.dequeue()) #prints 3
print(myQueue.size()) #prints 0
print(myQueue.dequeue()) #prints Queue Empty!Call the method printQueue() wherever necessary to ensure that it’s working.
Note: You will notice that we are not removing elements from the beginning and adding elements at the end. The reason for this is covered in the ‘implementation using arrays’ section below.
Queue implementation using deque
Deque is a library which, when imported, provides ready-made commands such as the append() command for enqueuing and the popleft() command for dequeuing.
#Importing the library from collections import deque #Creating a Queue queue = deque([1,5,8,9]) #Enqueuing elements to the Queue queue.append(7) #[1,5,8,9,7] queue.append(0) #[1,5,8,9,7,0] #Dequeuing elements from the Queue queue.popleft() #[5,8,9,7,0] queue.popleft() #[8,7,9,0] #Printing the elements of the Queue print(queue)
Try using the popleft() command after the queue is empty and see what you get. Post the ways in which you can handle this issue.
NOTE: Implementation 2 is more efficient as the insert operation in the list is costly! This is because whenever an element is inserted at position 0, all of the other elements have to be shifted by one position (it is similar to when people sitting on a bench push down to accommodate another person). We will discuss the efficiency of operations in detail in later tutorials.
Queue implementation using array
Python Lists have made it so easy to implement Queue. However, if you want to implement Queues language agnostically, you have to bear in mind the following points:
- Elements are added from the end and removed at the beginning of the Queue.
- Treat lists like arrays (fixed in size) – we can achieve it by virtually restricting the size of the list. This is done by ensuring that the list doesn’t grow beyond a fixed limit or size.
- Use a Tail pointer to keep a tab of the elements added to the Queue – the Tail pointer will always point to the next available space. For instance when there are three elements in the queue, Tail will point to the fourth place. When the queue is full, the tail pointer will be greater than the declared size.
- Use a Head pointer to keep a tab on the elements removed from the Queue – the Head pointer will point to the element to be dequeued next. For instance, if there are three elements in a queue, the Head pointer will be pointing to the first element. After one dequeue operation, the Head pointer will point to the second element in the queue. No element will be actually removed from the queue. This is because once an element is removed, the list automatically shifts all the other elements by one position to the left. This means that the position 0 will always contain an element, which is not how an actual queue works.
- Use a Reset method – this method is called to reset the queue, Tail and Head. For instance, if there are three elements in the queue then Head = 0, Tail = 4. Now, if we dequeue all three elements, the queue will be empty meaning Head = Tail = 4. So if you enqueue an element, it will happen at position 4 which is not correct. Hence it becomes necessary to reset these pointers to 0. Note that since we are not actually deleting elements, the list still contains the ‘deleted” elements, hence a new list needs to be created as well.
Algorithm
- Declare a list and an integer MaxSize, denoting a virtual maximum size of the Queue
- Head and Tail are initially set to 0
- Size method
- Calculates the number of elements in the queue -> Size = Tail – Head
- Reset method:
- Resets Tail and Head to 0
- Creates a new Queue (initializes queue to a new list)
- Enqueue operation:
- Check if Size is less than the MaxSize:
- If yes, append data to Queue and then increment Tail by 1
- If no, print Queue full message
- Check if Size is less than the MaxSize:
- Dequeue operation:
- Check if Size is greater than 0:
- If yes, pop the first element from the list and increment Head by 1
- If no:
- Call Reset method
- Print Queue empty message
- Check if Size is greater than 0:
Program
class Queue:
#Constructor
def __init__(self):
self.queue = list()
self.maxSize = 8
self.head = 0
self.tail = 0
#Adding elements
def enqueue(self,data):
#Checking if the queue is full
if self.size() >= self.maxSize:
return ("Queue Full")
self.queue.append(data)
self.tail += 1
return True
#Deleting elements
def dequeue(self):
#Checking if the queue is empty
if self.size() <= 0:
self.resetQueue()
return ("Queue Empty")
data = self.queue[self.head]
self.head+=1
return data
#Calculate size
def size(self):
return self.tail - self.head
#Reset queue
def resetQueue(self):
self.tail = 0
self.head = 0
self.queue = list()
q = Queue()
print(q.enqueue(1))#prints True
print(q.enqueue(2))#prints True
print(q.enqueue(3))#prints True
print(q.enqueue(4))#prints True
print(q.enqueue(5))#prints True
print(q.enqueue(6))#prints True
print(q.enqueue(7))#prints True
print(q.enqueue(8))#prints True
print(q.enqueue(9))#prints Queue Full!
print(q.size())#prints 8
print(q.dequeue())#prints 8
print(q.dequeue())#prints 7
print(q.dequeue())#prints 6
print(q.dequeue())#prints 5
print(q.dequeue())#prints 4
print(q.dequeue())#prints 3
print(q.dequeue())#prints 2
print(q.dequeue())#prints 1
print(q.dequeue())#prints Queue Empty
#Queue is reset here
print(q.enqueue(1))#prints True
print(q.enqueue(2))#prints True
print(q.enqueue(3))#prints True
print(q.enqueue(4))#prints TrueNote: Element 9 was not added to the Queue and hence the size of the Queue remains 8
Apart from the methods described above, you can add methods which could return the element at the start of the queue, check if the queue is empty etc.
Conclusion
That’s it for this tutorial. Be sure to learn the applications of Queue. Plus, stay tuned with us here on PythonCentral to learn more about other types of Queues like Circular Queue and Priority Queue. Happy Pythoning!