Basics of Python – Built-in Types
In this Page, We are Providing Basics of Python – Built-in Types. Students can visit for more Detail and Explanation of Python Handwritten Notes Pdf.
Basics of Python – Built-in Types
Built-in types
This section describes the standard data types that are built into the interpreter. There are various built-in data types, for e.g., numeric, sequence, mapping, etc., but this book will cover few types. Schematic representation of various built-in types is shown in figure 2-1.
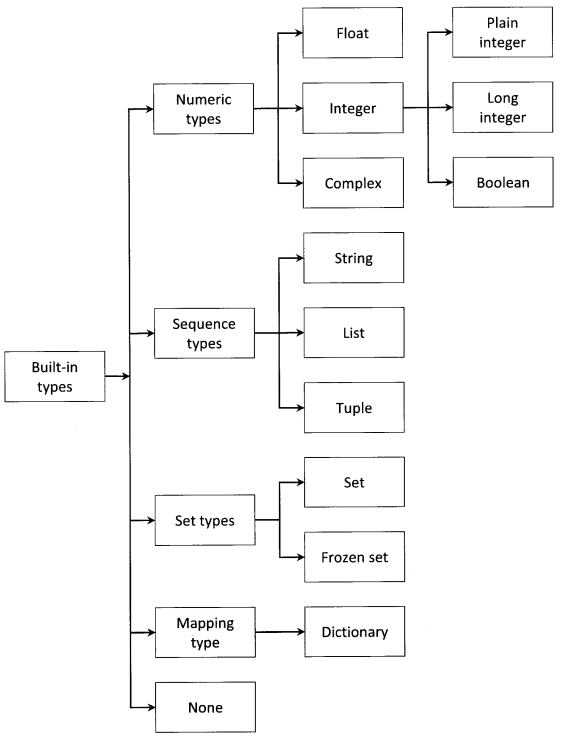
Numeric types
There are three distinct numeric types: integer, floating-point number, and complex number.
Integer
Integer can be sub-classified into three types:
Plain integer
Plain integer (or simply ” integer “) represents an integer number in the range -2147483648 through 2147483647. When the result of an operation would fall outside this range, the result is normally returned as a long integer.
>>> a=2147483647 >>> type (a) <type ' int '> >>> a=a+1 >>> type (a) <type ' long '> >>> a=-2147483648 >>> type (a) <type ' int '> >>> a=a-1 >>> type (a) <type ' long ’>
The built-in function int(x = 0) converts a number or string x to an integer or returns 0 if no arguments are given.
>>> a =' 57 ' >>> type (a) <type ' str '> >>> a = int (a) >>> a 57 >>> type (a) <type ' int '> >>> a = 5.7 >>> type (a) <type ' float '> >>> a = int (a) >>> a 5 >>> type (a) <type ' int '> >>> int( ) 0
Long integer
This represents integer numbers in a virtually unlimited range, subject to available memory. The built-in function long (x=0) converts a string or number to a long integer. If the argument is a string, it must contain a possibly signed number. If no argument is given, OL is returned.
>>> a = 5
>>> type (a)
<type ' int '>
>>> a = long (a)
>>> a
5L
>>> type (a)
<type ' long '>
>>> long ( )
OL
>>> long (5)
5L
>>> long (5.8)
5L
>>> long(' 5 ')
5L
>>> long(' -5 ')
-5LInteger literals with an L or 1 suffix yield long integers (L is preferred because 11 looks too much like eleven).
>>> a=10L >>> type (a) <type ' long '> >>> a=101 >>> type (a) <type ' long '>
The following expressions are interesting.
>>> import sys >>> a=sys.maxint >>> a 2147483647 >>> type (a) <type ' int '> >>> a=a+1 >>> a 21474836 48L >>> type (a) <type ' long ’>
Boolean
This represents the truth values False and True. The boolean type is a sub-type of plain integer, and boolean values behave like the values 0 and 1. The built-in function bool ( ) converts a value to boolean, using the standard truth testing procedure.
>>> bool ( )
False
>>> a=5
>>> bool (a)
True
>>> bool (0)
False
>>> bool( ' hi ' )
True
>>> bool(None)
False
>>> bool(' ')
False
>>> bool(False)
False
>>> bool("False" )
True
>>> bool(5 > 3)
TrueFloating point number
This represents a decimal point number. Python supports only double-precision floating-point numbers (occupies 8 bytes of memory) and does not support single-precision floating-point numbers (occupies 4 bytes of memory). The built-in function float ( ) converts a string or a number to a floating-point number.
>>> a = 57 >>> type (a) <type ' int '> >>> a = float (a) >>> a 57.0 >>> type (a) <type ' float '> >>> a = ' 65 ' >>> type (a) <type ' str ' > >>> a = float (a) >>> a 65.0 >>> type (a) <type ' float '> >>> a = 1e308 >>> a 1e+30 8 >>> type (a) <type ' float '> >>> a = 1e309 >>> a inf >>> type (a) <type ' float '>
Complex number
This represents complex numbers having real and imaginary parts. The built-in function complex () is used to convert numbers or strings to complex numbers.
>>> a = 5.3 >>> a = complex (a) >>> a (5 . 3 + 0 j) >>> type (a) <type ' complex '> >>> a = complex ( ) >>> a 0 j >>> type (a) <type ' complex '>
Appending j or J to numeric literal yields a complex number.
>>> a = 3 . 4 j >>> a 3 . 4 j >>> type (a) <type ' complex '> >>> a = 3 . 5 + 4 . 9 j >>> type (a) <type ' complex '> >>> a = 3 . 5+4 . 9 J >>> type (a) <type ' complex '>
The real and imaginary parts of a complex number z can be retrieved through the attributes z. real and z. imag.
a=3 . 5 + 4 . 9 J >>> a . real 3 . 5 >>> a . imag 4 . 9
Sequence Types
These represent finite ordered sets, usually indexed by non-negative numbers. When the length of a sequence is n, the index set contains the numbers 0, 1, . . ., n-1. Item i of sequence a is selected by a [i]. There are seven sequence types: string, Unicode string, list, tuple, bytearray, buffer, and xrange objects.
The sequence can be mutable or immutable. The immutable sequence is a sequence that cannot be changed after it is created. If an immutable sequence object contains references to other objects, these other objects may be mutable and may be changed; however, the collection of objects directly referenced by an immutable object cannot change. The mutable sequence is a sequence that can be changed after it is created. There are two intrinsic mutable sequence types: list and byte array.
Iterable is an object capable of returning its members one at a time. Examples of iterables include all sequence types (such as list, str, and tuple) and some non-sequence types like diet and file, etc. Iterables can be used in a for loop and in many other places where a sequence is needed (zip(), map (), …). When an iterable object is passed as an argument to the built-in function iter (), it returns an iterator for the object. An iterator is an object representing a stream of data; repeated calls to the iterator’s next () method return successive items in the stream. When no more data are available, a Stoplteration exception is raised instead.
Some of the sequence types are discussed below:
String
It is a sequence type such that its value can be characters, symbols, or numbers. Please note that string is immutable.
>>> a=' Python : 2 . 7 ' >>> type (a) <type ' str ’> >>> a [2 ] =' S ' Traceback (most recent call last) : File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment
The built-in function str (object =’ ‘ ) returns a string containing a nicely printable representation of an object. For strings, this returns the string itself. If no argument is given, an empty string is returned.
>>> a=57.3 >>> type(a) <type 'float'> >>> a=str(a) >>> a ' 57.3 ' >>> type (a) <type ' str '>
Tuple
A tuple is a comma-separated sequence of arbitrary Python objects enclosed in parenthesis (round brackets). Please note that the tuple is immutable. A tuple is discussed in detail in chapter 4.
>>> a=(1 , 2 , 3 ,4) >>> type (a) <type ' tuple '> 'a', 'b', 'c')
List
The list is a comma-separated sequence of arbitrary Python objects enclosed in square brackets. Please note that list is mutable. More information on the list is provided in chapter 4.
>>> a=[1, 2 ,3, 4] >>> type(a) <type ' list '>
Set types
These represent an unordered, finite set of unique objects. As such, it cannot be indexed by any subscript, however, they can be iterated over. Common uses of sets are fast membership testing, removing duplicates from a sequence, and computing mathematical operations such as intersection, union, difference, and symmetric difference. There are two set types:
Set
This represents a mutable set. It is created by the built-in function set (), and can be modified afterward by several methods, such as add () remove (), etc. More information on the set is given in chapter 4.
>>> set1=set ( ) # A new empty set
>>> set1.add (" cat ") # Add a single member
>>> set1.update ([" dog "," mouse "]) # Add several members
>>> set1.remove ("mouse") # Remove member
>>> set1
set([' dog ', ' cat '])
>>> set2=set([" dog "," mouse "])
>>> print set1&set2 # Intersection
set ( [' dog ' ] )
>>> print set1 | set2 # Union
set([' mouse ', ' dog ', ' cat '])The set ( [ iterable ] ) return a new set object, optionally with elements taken from iterable.
Frozenset
This represents an immutable set. It is created by a built-in function frozenset ( ). As a frozenset is immutable, it can be used again as an element of another set, or as a dictionary key.
>>> frozenset ( )
frozenset ( [ ] )
>>> frozenset (' aeiou ')
frozenset{ [' a ', ' i ',' e ',' u ',' o '])
>>> frozenset ( [0, 0, 0, 44, 0, 44, 18] )
frozenset (10, 18, 44])The frozenset ( [iterable] ) return return a new frozenset object, optionally with elements taken from iterable.
Mapping Types
This represents a container object that supports arbitrary key lookups. The notation a [k] selects the value indexed by key k from the mapping a; this can be used in expressions and as the target of assignments or del statements. The built-in function len () returns the number of items in a mapping. Currently, there is a single mapping type:
Dictionary
A dictionary is a mutable collection of unordered values accessed by key rather than by index. In the dictionary, arbitrary keys are mapped to values. More information is provided in chapter 4.
>>> dict1={"john":34,"mike":56}
>>> dict1[" michael "] = 42
>>> dict1
{' mike ' : 56, ' john ' : 34, ' michael ' : 42}
>>> dictl[" mike "]
56None
This signifies the absence of a value in a situation, e.g., it is returned from a function that does not explicitly return anything. Its truth value is False.
Some other built-in types such as function, method, class, class instance, file, module, etc. are discussed in later chapters.