What is PDF?
PDFs are a popular format for distributing text. PDF is an abbreviation for Portable Document Format, and it utilizes the .pdf file extension. Adobe Systems designed it in the early 1990s.
Reading PDF documents in Python can assist you in automating a wide range of operations.
In many scenarios, we must work with table data when programming. However, if they are in the PDF, we must first extract them.
Let us see the two simple methods for extracting tables from PDFs in Python.
- Using Tabulate
- Using Camelot
Extracting Tables from a PDF in Python
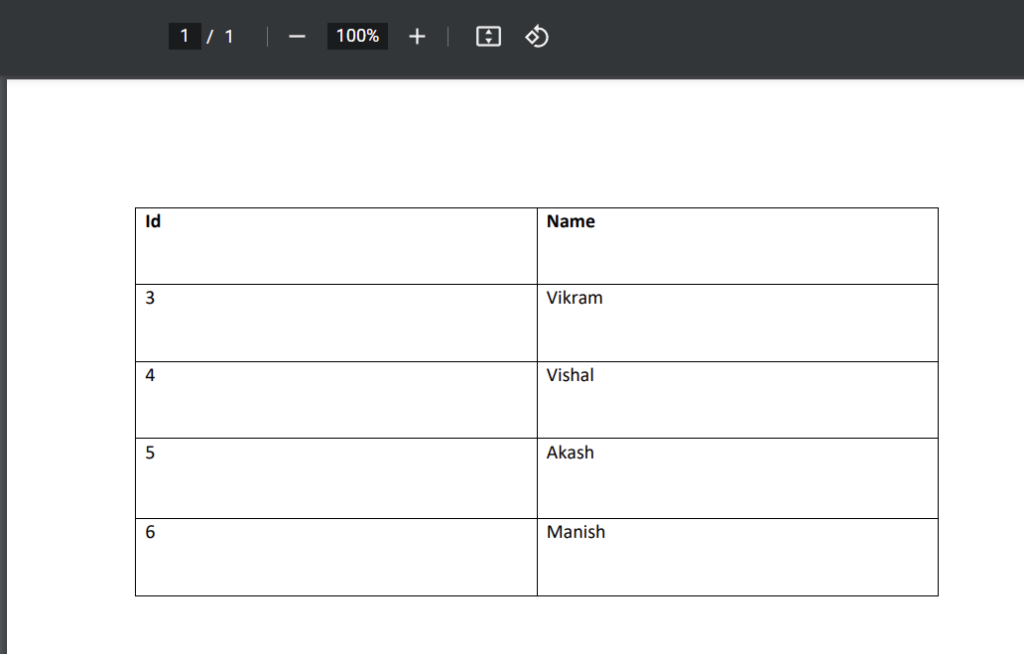
Here we consider the PDF say “demopdf.pdf” which has the following table data:
demopdf.pdf:
Using Tabulate
In Python, you can pretty-print tabular data using a library and a command-line application.
The library’s primary use cases are as follows:
- Without difficulty, print small tables: Formatting is dictated by the data itself and requires only one function call.
- tabular data writing for lightweight plain-text markup: numerous output formats appropriate for additional modification or transformation
- readable display of mixed textual and numerical data: Smart column alignment, customizable number formatting, and decimal point placement
Install the below commands before working on tabulate for extracting tables from a PDF.
pip install tabula-py pip install tabulate
Code
Approach:
- Import function from tabula module using the import keyword
- Import tabulate function from tabulate module using the import keyword
- Read all the pages and extract the tables from the PDF using the read_pdf() function by passing pdf name, pages=”all” as arguments to it.
- Pass the above tables in a pdf varibale to the tabulate() function to rearrange the data from the table.
- The Exit of the Program.
Below is the implementation:
# Import function from tabula module using the import keyword
from tabula import read_pdf
# Import tabulate function from tabulate module using the import keyword
from tabulate import tabulate
# Read all the pages and extract the tables from the PDF using the read_pdf() function
# by passing pdf name, pages="all" as arguments to it.
tables_in_pdf = read_pdf("demopdf.pdf", pages="all")
# Pass the above tables in a pdf varibale to the tabulate() function to rearrange
# the data from the table
print(tabulate(tables_in_pdf))Output:
---------------------- ------------------------- 0 3 0 Vikram 1 4 1 Vishal 2 5 2 Akash 3 6 3 Manish Name: Id, dtype: int64 Name: Name, dtype: object ---------------------- -------------------------