
In this tutorial, we are going to discuss different ways to add columns to the dataframe in pandas. Moreover, you can have an idea about the Pandas Add Column, Adding a new column to the existing DataFrame in Pandas and many more from the below explained various methods.
- Pandas Add Column
- Add column to dataframe in pandas using [] operator
- Add new column to DataFrame with same default value
- Add column based on another column
- Append column to dataFrame using assign() function
- Add a columns in DataFrame based on other column using lambda function
- Add new column to Dataframe using insert()
- Add a column to Dataframe by dictionary
Pandas Add Column
Pandas is one such data analytics library created explicitly for Python to implement data manipulation and data analysis. The Pandas library made of specific data structures and operations to deal with numerical tables, analyzing data, and work with time series.
Basically, there are three ways to add columns to pandas i.e., Using [] operator, using assign() function & using insert().
We will discuss it all one by one.
First, let’s create a dataframe object,
import pandas as pd
# List of Tuples
students = [('Rakesh', 34, 'Agra', 'India'),
('Rekha', 30, 'Pune', 'India'),
('Suhail', 31, 'Mumbai', 'India'),
('Neelam', 32, 'Bangalore', 'India'),
('Jay', 16, 'Bengal', 'India'),
('Mahak', 17, 'Varanasi', 'India')]
# Create a DataFrame object
df_obj = pd.DataFrame(students,
columns=['Name', 'Age', 'City', 'Country'],
index=['a', 'b', 'c', 'd', 'e', 'f'])
print(df_obj )Output:
Name Age City Country a Rakesh 34 Agra India b Rekha 30 Pune India c Suhail 31 Mumbai India d Neelam 32 Bangalore India e Jay 16 Bengal India f Mahak 17 Varanasi India
Do Check:
- Pandas: Delete last column of dataframe in python
- Pandas: Loop or Iterate over all or certain columns of a dataframe
Add column to dataframe in pandas using [] operator
import pandas as pd
# List of Tuples
students = [('Rakesh', 34, 'Agra', 'India'),
('Rekha', 30, 'Pune', 'India'),
('Suhail', 31, 'Mumbai', 'India'),
('Neelam', 32, 'Bangalore', 'India'),
('Jay', 16, 'Bengal', 'India'),
('Mahak', 17, 'Varanasi', 'India')]
# Create a DataFrame object
df_obj = pd.DataFrame(students,
columns=['Name', 'Age', 'City', 'Country'],
index=['a', 'b', 'c', 'd', 'e', 'f'])
# Add column with Name Score
df_obj['Score'] = [10, 20, 45, 33, 22, 11]
print(df_obj )Output:
Name Age City Country Score a Rakesh 34 Agra India 10 b Rekha 30 Pune India 20 c Suhail 31 Mumbai India 45 d Neelam 32 Bangalore India 33 e Jay 16 Bengal India 22 f Mahak 17 Varanasi India 11
So in the above example, you have seen we have added one extra column ‘score’ in our dataframe. So in this, we add a new column to Dataframe with Values in the list. In the above dataframe, there is no column name ‘score’ that’s why it added if there is any column with the same name that already exists then it will replace all its values.
Add new column to DataFrame with same default value
import pandas as pd
# List of Tuples
students = [('Rakesh', 34, 'Agra', 'India'),
('Rekha', 30, 'Pune', 'India'),
('Suhail', 31, 'Mumbai', 'India'),
('Neelam', 32, 'Bangalore', 'India'),
('Jay', 16, 'Bengal', 'India'),
('Mahak', 17, 'Varanasi', 'India')]
# Create a DataFrame object
df_obj = pd.DataFrame(students,
columns=['Name', 'Age', 'City', 'Country'],
index=['a', 'b', 'c', 'd', 'e', 'f'])
df_obj['Total'] = 100
print(df_obj)Output:
Name Age City Country Total a Rakesh 34 Agra India 100 b Rekha 30 Pune India 100 c Suhail 31 Mumbai India 100 d Neelam 32 Bangalore India 100 e Jay 16 Bengal India 100 f Mahak 17 Varanasi India 100
So in the above example, we have added a new column ‘Total’ with the same value of 100 in each index.
Add column based on another column
Let’s add a new column ‘Percentage‘ where entrance at each index will be added by the values in other columns at that index i.e.,
df_obj['Percentage'] = (df_obj['Marks'] / df_obj['Total']) * 100 df_obj
Output:
Name Age City Country Marks Total Percentage a jack 34 Sydeny Australia 10 50 20.0 b Riti 30 Delhi India 20 50 40.0 c Vikas 31 Mumbai India 45 50 90.0 d Neelu 32 Bangalore India 33 50 66.0 e John 16 New York US 22 50 44.0 f Mike 17 las vegas US 11 50 22.0
Append column to dataFrame using assign() function
So for this, we are going to use the same dataframe which we have created in starting.
Syntax:
DataFrame.assign(**kwargs)
Let’s add columns in DataFrame using assign().
import pandas as pd
# List of Tuples
students = [('Rakesh', 34, 'Agra', 'India'),
('Rekha', 30, 'Pune', 'India'),
('Suhail', 31, 'Mumbai', 'India'),
('Neelam', 32, 'Bangalore', 'India'),
('Jay', 16, 'Bengal', 'India'),
('Mahak', 17, 'Varanasi', 'India')]
# Create a DataFrame object
df_obj = pd.DataFrame(students,
columns=['Name', 'Age', 'City', 'Country'],
index=['a', 'b', 'c', 'd', 'e', 'f'])
mod_fd = df_obj.assign(Marks=[10, 20, 45, 33, 22, 11])
print(mod_fd)
Output:
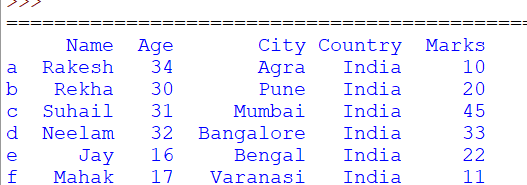
It will return a new dataframe with a new column ‘Marks’ in that Dataframe. Values provided in the list will be used as column values.
Add column in DataFrame based on other column using lambda function
In this method using two existing columns i.e, score and total value we are going to create a new column i.e..’ percentage’.
import pandas as pd
# List of Tuples
students = [('Rakesh', 34, 'Agra', 'India'),
('Rekha', 30, 'Pune', 'India'),
('Suhail', 31, 'Mumbai', 'India'),
('Neelam', 32, 'Bangalore', 'India'),
('Jay', 16, 'Bengal', 'India'),
('Mahak', 17, 'Varanasi', 'India')]
# Create a DataFrame object
df_obj = pd.DataFrame(students, columns=['Name', 'Age', 'City', 'Country'],
index=['a', 'b', 'c', 'd', 'e', 'f'])
df_obj['Score'] = [10, 20, 45, 33, 22, 11]
df_obj['Total'] = 100
df_obj = df_obj.assign(Percentage=lambda x: (x['Score'] / x['Total']) * 100)
print(df_obj)
Output:
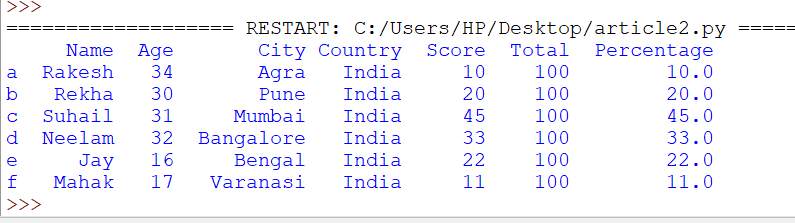
Add new column to Dataframe using insert()
import pandas as pd
# List of Tuples
students = [('Rakesh', 34, 'Agra', 'India'),
('Rekha', 30, 'Pune', 'India'),
('Suhail', 31, 'Mumbai', 'India'),
('Neelam', 32, 'Bangalore', 'India'),
('Jay', 16, 'Bengal', 'India'),
('Mahak', 17, 'Varanasi', 'India')]
# Create a DataFrame object
df_obj = pd.DataFrame(students, columns=['Name', 'Age', 'City', 'Country'],
index=['a', 'b', 'c', 'd', 'e', 'f'])
# Insert column at the 2nd position of Dataframe
df_obj.insert(2, "Marks", [10, 20, 45, 33, 22, 11], True)
print(df_obj)
Output:
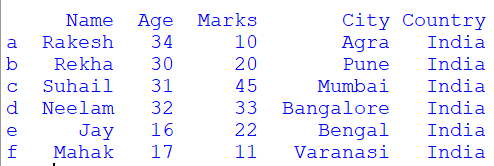
In other examples, we have added a new column at the end of the dataframe, but in the above example, we insert a new column in between the other columns of the dataframe, then we can use the insert() function.
Add a column to Dataframe by dictionary
import pandas as pd
# List of Tuples
students = [('Rakesh', 34, 'Agra', 'India'),
('Rekha', 30, 'Pune', 'India'),
('Suhail', 31, 'Mumbai', 'India'),
('Neelam', 32, 'Bangalore', 'India'),
('Jay', 16, 'Bengal', 'India'),
('Mahak', 17, 'Varanasi', 'India')]
# Create a DataFrame object
df_obj = pd.DataFrame(students, columns=['Name', 'Age', 'City', 'Country'],
index=['a', 'b', 'c', 'd', 'e', 'f'])
ids = [11, 12, 13, 14, 15, 16]
# Provide 'ID' as the column name and for values provide dictionary
df_obj['ID'] = dict(zip(ids, df_obj['Name']))
print(df_obj)
Output:
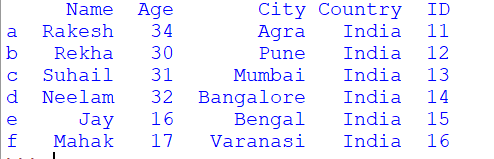
Want to expert in the python programming language? Exploring Python Data Analysis using Pandas tutorial changes your knowledge from basic to advance level in python concepts.
Read more Articles on Python Data Analysis Using Padas – Add Contents to a Dataframe