How to Make a Discord Bot Python
In a world where video games are so important to so many people, communication and community around games are vital. Discord offers both of those and more in one well-designed package. In this tutorial, you’ll learn how to make a Discord bot in Python so that you can make the most of this fantastic platform.
What Is Discord?
Discord is a voice and text communication platform for gamers.
Players, streamers, and developers use Discord to discuss games, answer questions, chat while they play, and much more. It even has a game store, complete with critical reviews and a subscription service. It is nearly a one-stop shop for gaming communities.
While there are many things you can build using Discord’s APIs this tutorial will focus on a particular learning outcome: how to make a Discord bot in Python.
What Is a Bot?
Discord is growing in popularity. As such, automated processes, such as banning inappropriate users and reacting to user requests are vital for a community to thrive and grow.
Automated programs that look and act like users and automatically respond to events and commands on Discord are called bot users. Discord bot users (or just bots) have nearly unlimited application.
How to Make a Discord Bot in the Developer Portal:
Before you can dive into any Python code to handle events and create exciting automations, you need to first create a few Discord components:
- An account
- An application
- A bot
- A guild
You’ll learn more about each piece in the following sections.
Once you’ve created all of these components, you’ll tie them together by registering your bot with your guild.
Creating a Discord Account
The first thing you’ll see is a landing page where you’ll need to either login, if you have an existing account, or create a new account:
If you need to create a new account, then click on the Register button below Login and enter your account information.
Once you’re finished, you’ll be redirected to the Developer Portal home page, where you’ll create your application.
Creating an Application:
An application allows you to interact with Discord’s APIs by providing authentication tokens, designating permissions, and so on.
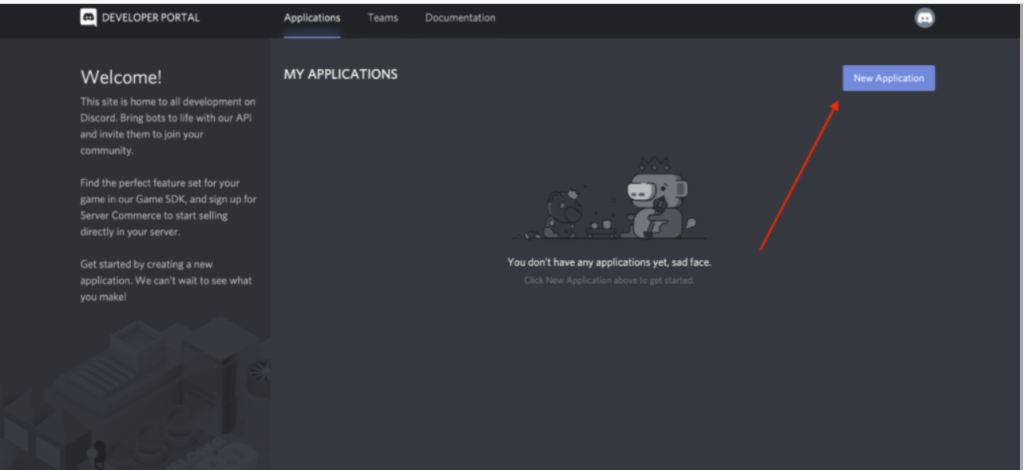
To create a new application, select New Application:
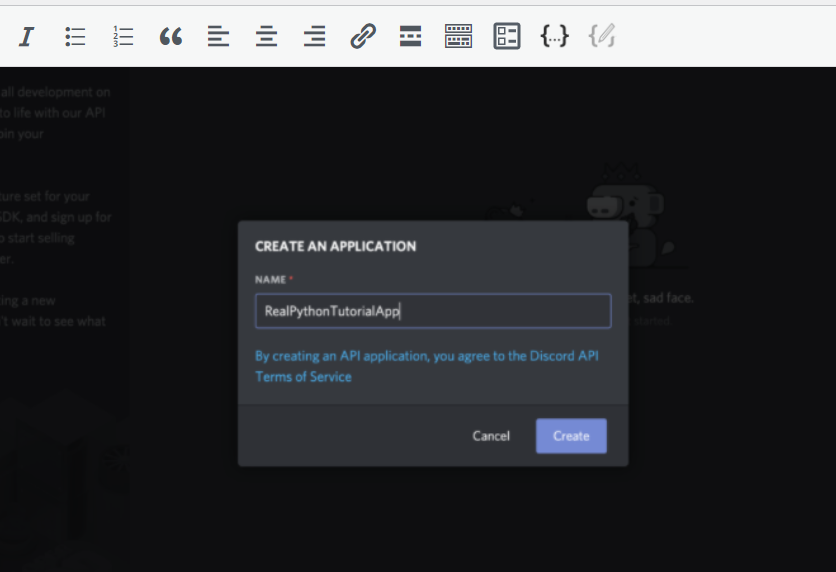
Next, you’ll be prompted to name your application. Select a name and click Create:
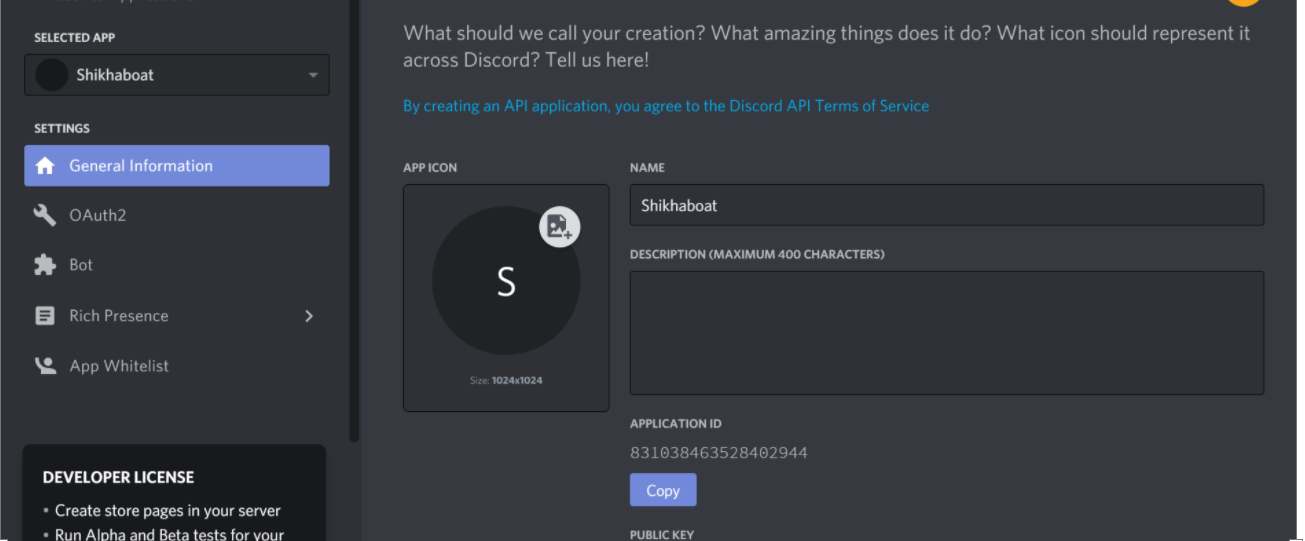
Congratulations! You made a Discord application. On the resulting screen, you can see information about your application:
Keep in mind that any program that interacts with Discord APIs requires a Discord application, not just bots. Bot-related APIs are only a subset of Discord’s total interface.
However, since this tutorial is about how to make a Discord bot, navigate to the Bot tab on the left-hand navigation list.
Creating a Bot
As you learned in the previous sections, a bot user is one that listens to and automatically reacts to certain events and commands on Discord.
For your code to actually be manifested on Discord, you’ll need to create a bot user. To do so, select Add Bot:
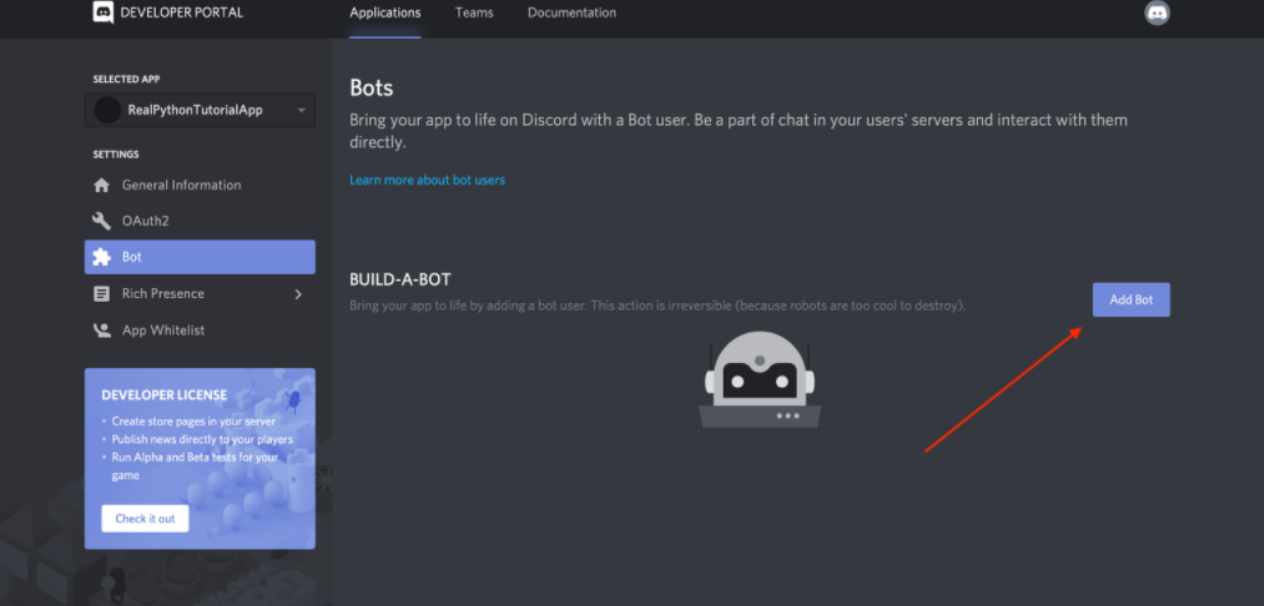
Once you confirm that you want to add the bot to your application, you’ll see the new bot user in the portal:
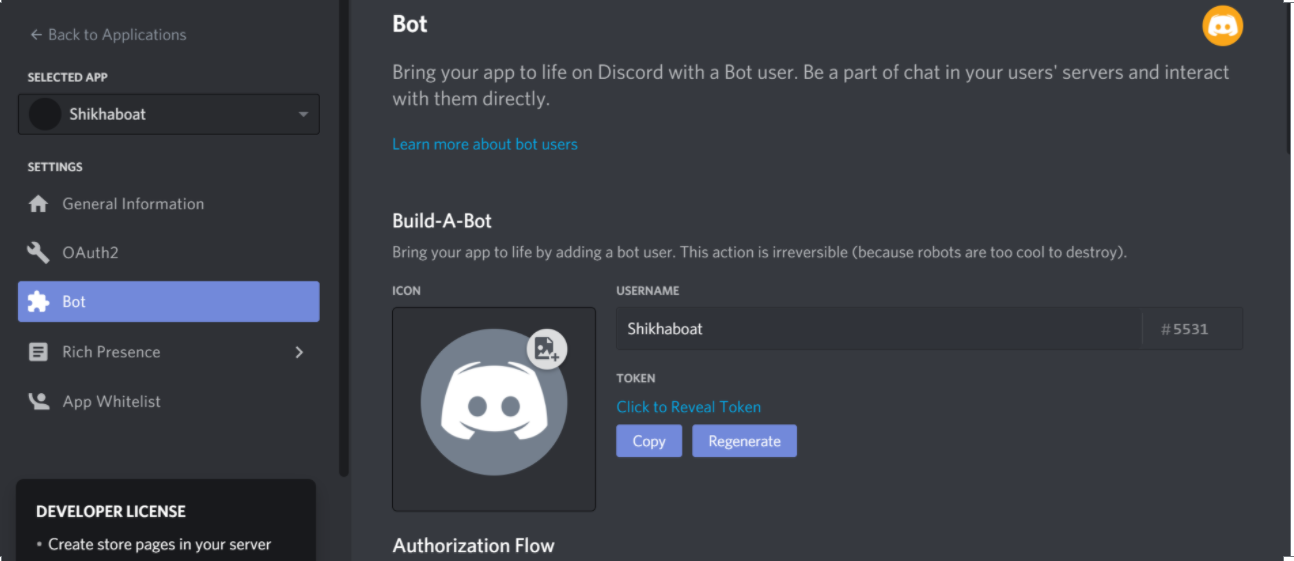
Now, the bot’s all set and ready to go, but to where?
A bot user is not useful if it’s not interacting with other users. Next, you’ll create a guild so that your bot can interact with other users.
Creating a Guild
A guild (or a server, as it is often called in Discord’s user interface) is a specific group of channels where users congregate to chat.
You’d start by creating a guild. Then, in your guild, you could have multiple channels, such as:
- General Discussion: A channel for users to talk about whatever they want
- Spoilers, Beware: A channel for users who have finished your game to talk about all the end game reveals
- Announcements: A channel for you to announce game updates and for users to discuss them
Once you’ve created your guild, you’d invite other users to populate it.
So, to create a guild, head to your Discord home page:
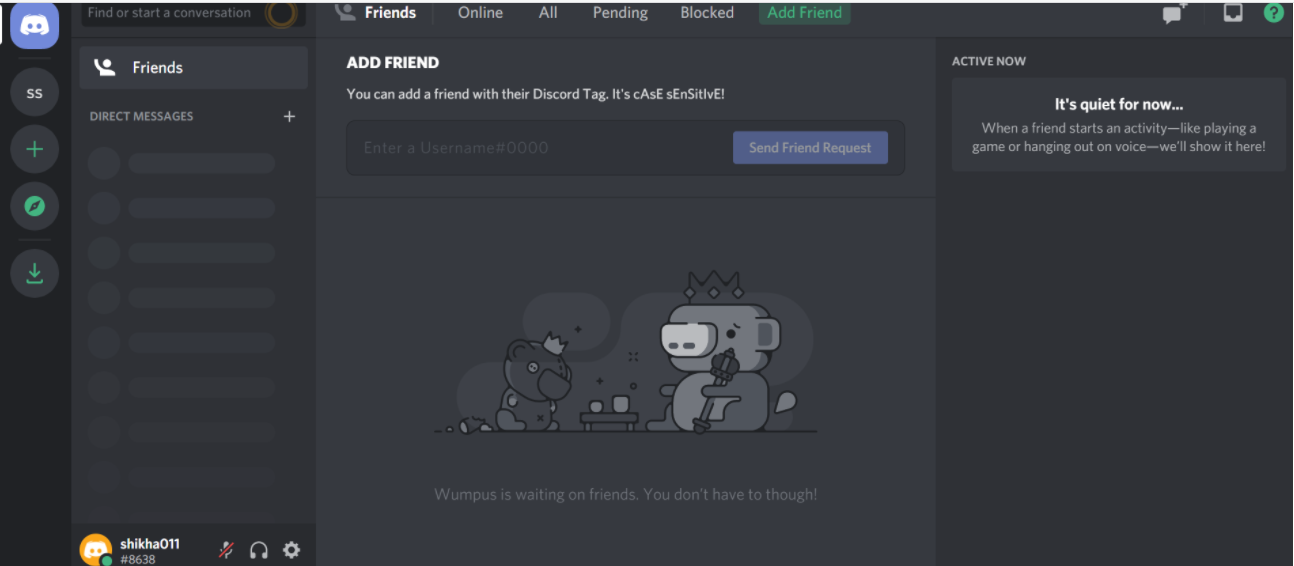
From this home page, you can view and add friends, direct messages, and guilds. From here, select the + icon on the left-hand side of the web page to Add a Server:
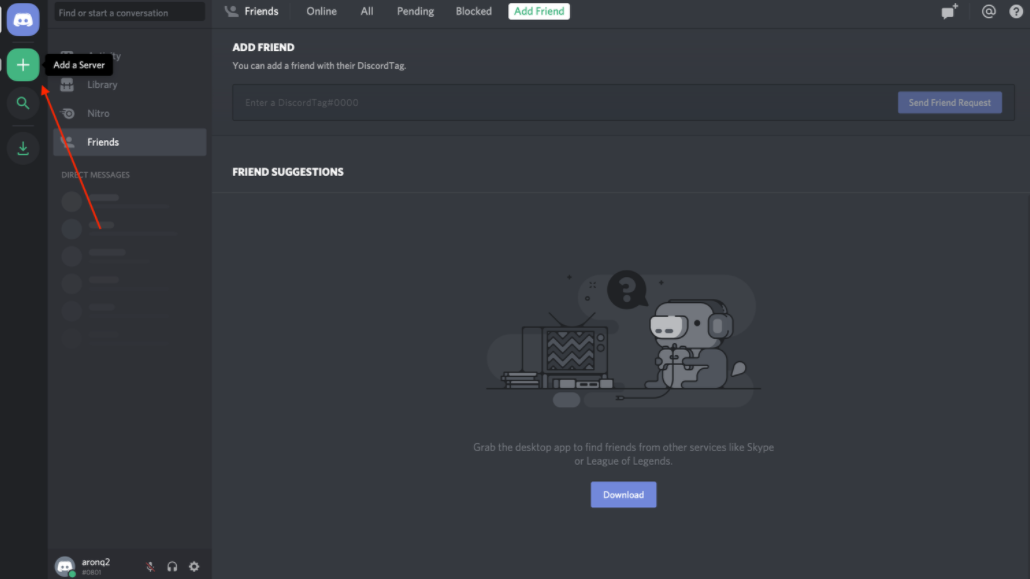
This will present two options, Create a server and Join a Server. In this case, select Create a server and enter a name for your guild.
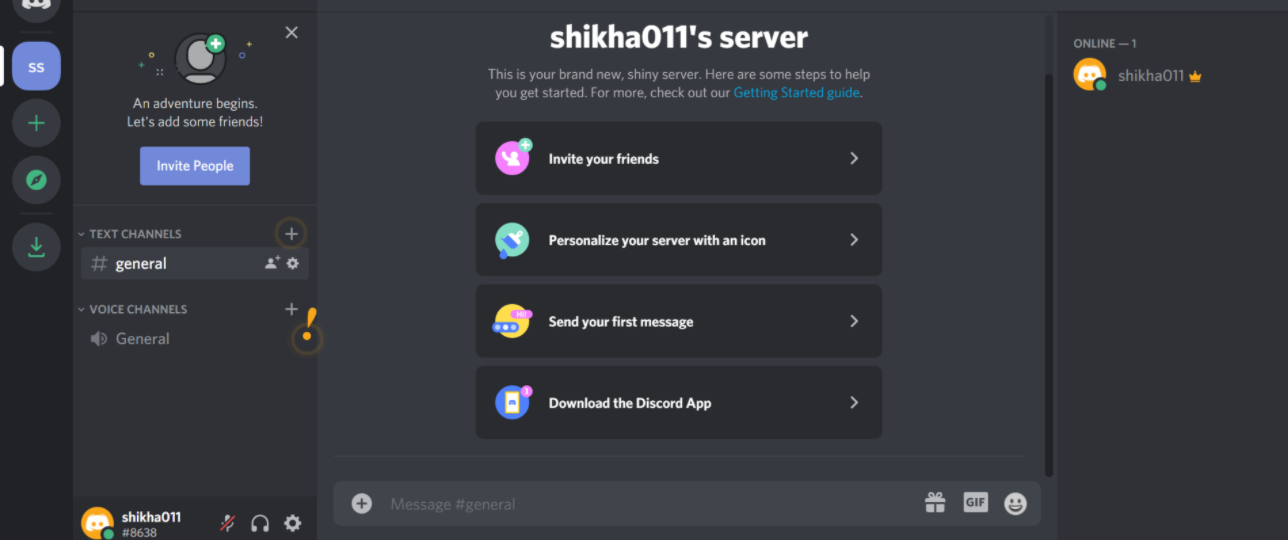
Once you’ve finished creating your guild, you’ll be able to see the users on the right-hand side and the channels on the left.
The final step on Discord is to register your bot with your new guild.
Adding a Bot to a Guild
A bot can’t accept invites like a normal user can. Instead, you’ll add your bot using the OAuth2 protocol.
To do so, head back to the Developer Portal and select the OAuth2 page from the left-hand navigation:
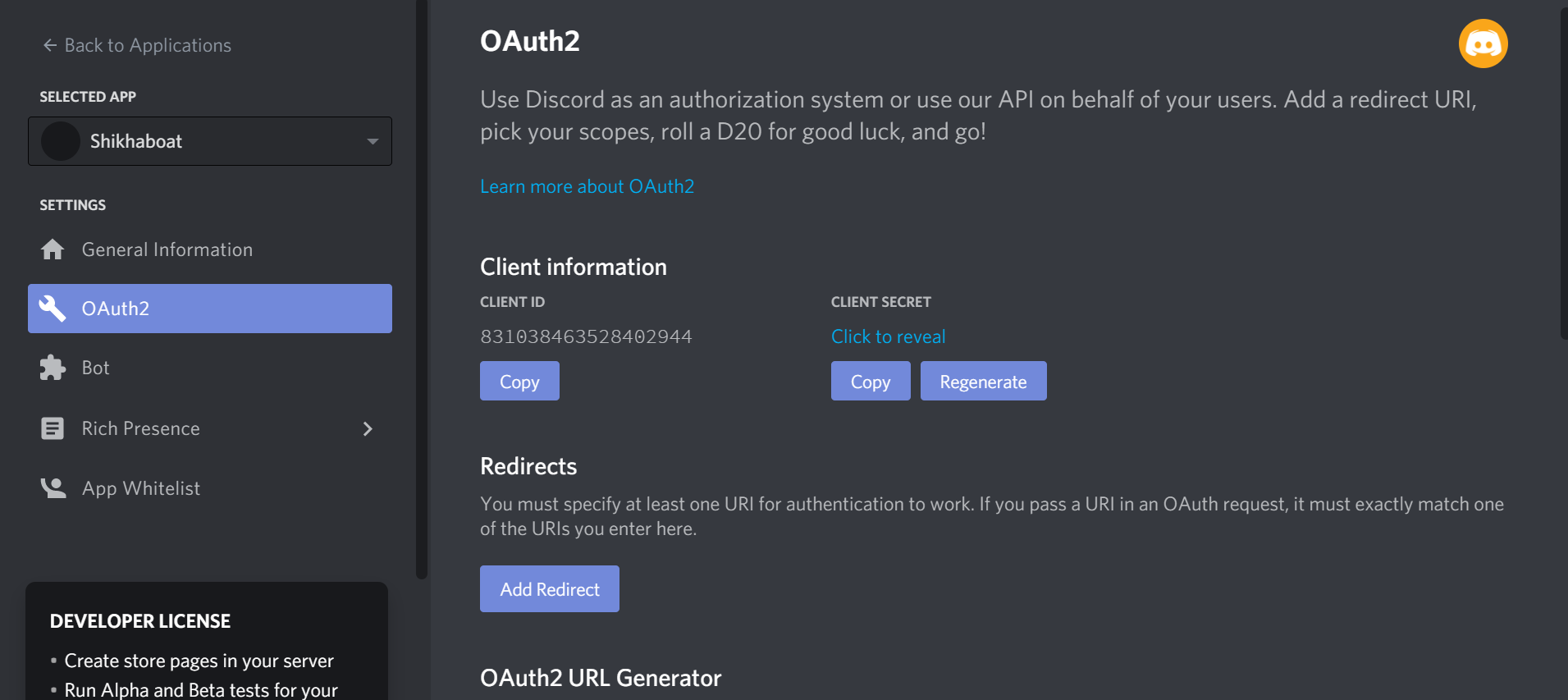
From this window, you’ll see the OAuth2 URL Generator.
This tool generates an authorization URL that hits Discord’s OAuth2 API and authorizes API access using your application’s credentials.
In this case, you’ll want to grant your application’s bot user access to Discord APIs using your application’s OAuth2 credentials.
To do this, scroll down and select bot from the SCOPES options and Administrator from BOT PERMISSIONS:
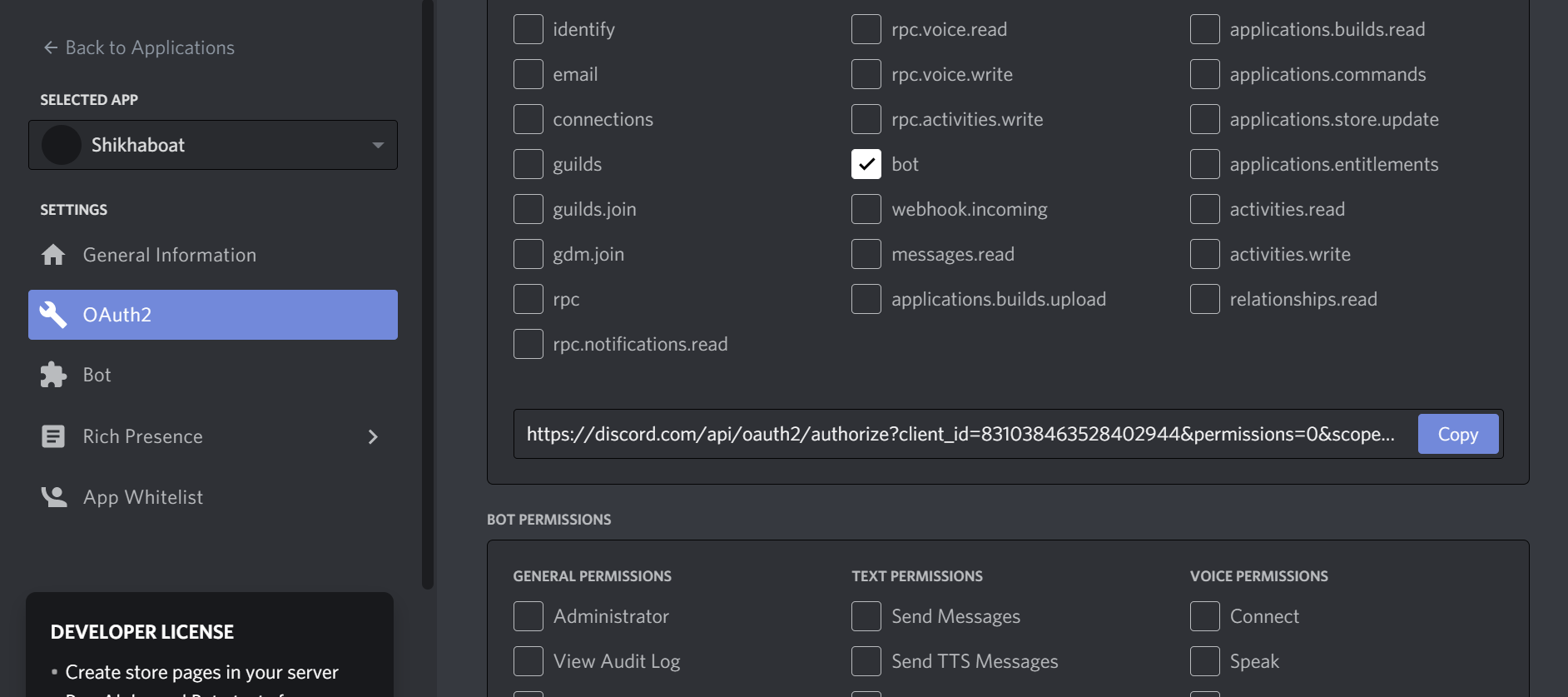
Now, Discord has generated your application’s authorization URL with the selected scope and permissions.
Select Copy beside the URL that was generated for you, paste it into your browser, and select your guild from the dropdown options:
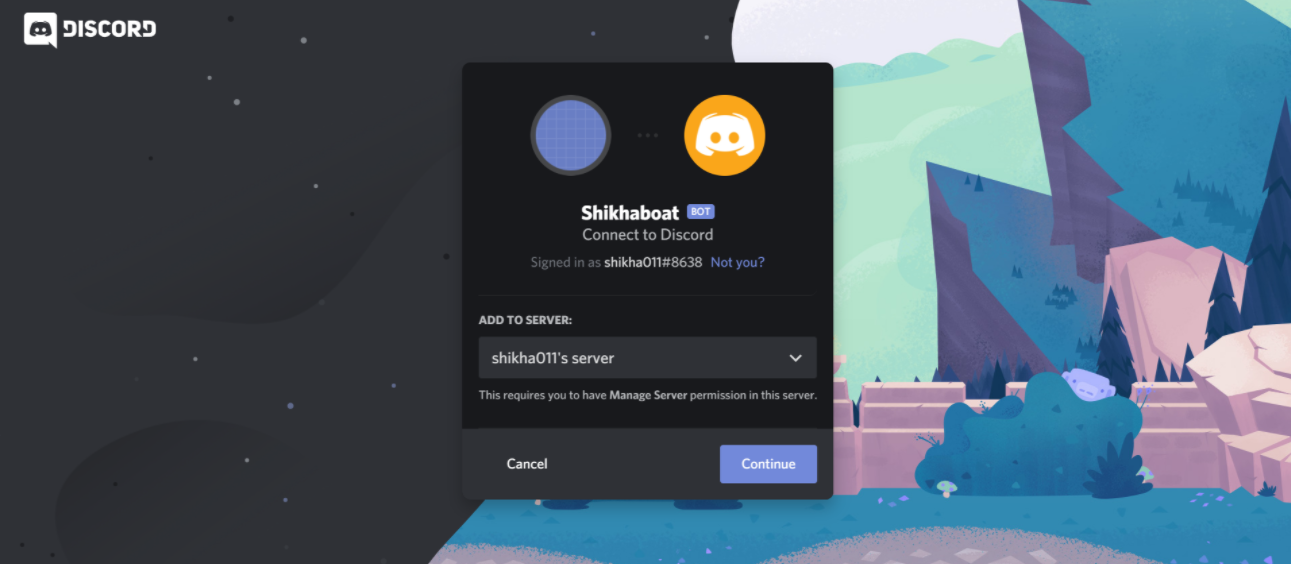
Click Authorize, and you’re done!

If you go back to your guild, then you’ll see that the bot has been added:
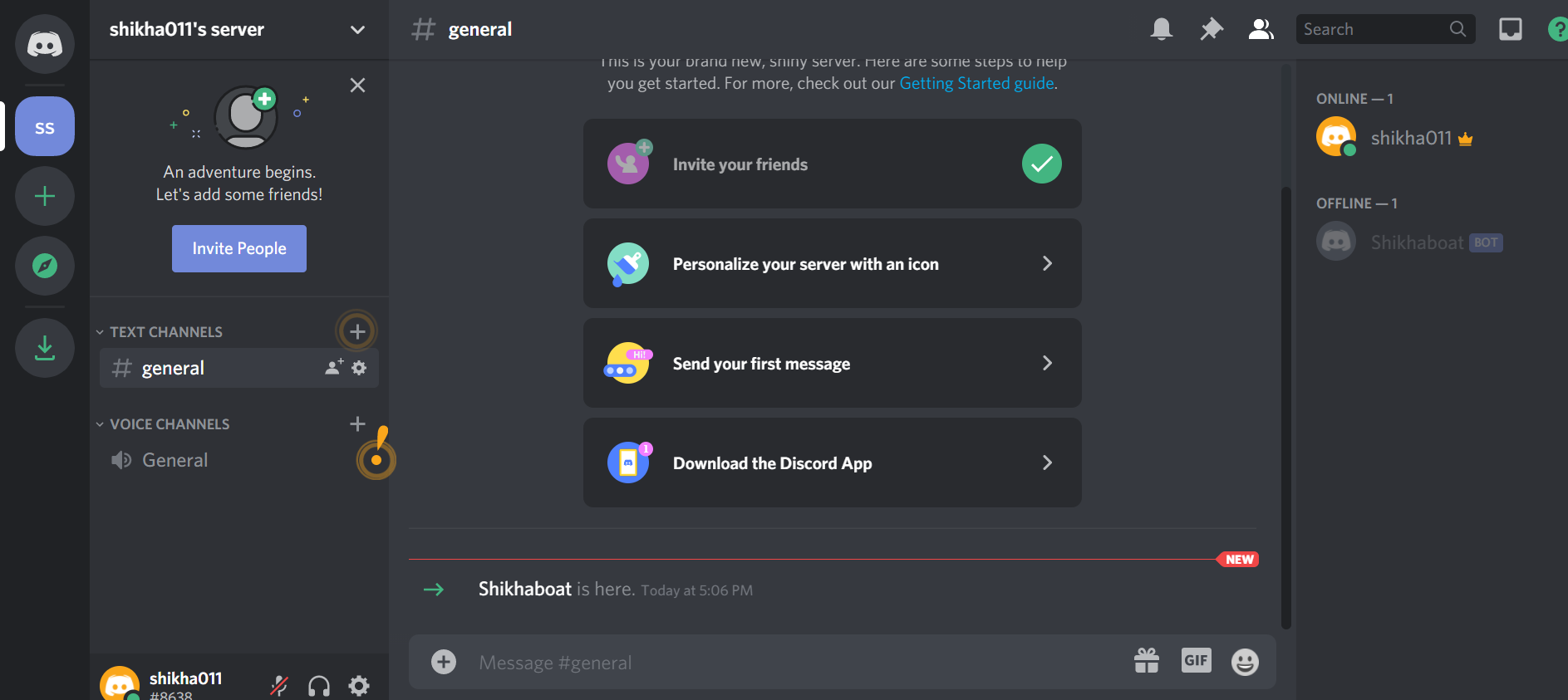
In summary, you’ve created:
- An application that your bot will use to authenticate with Discord’s APIs
- A bot user that you’ll use to interact with other users and events in your guild
- A guild in which your user account and your bot user will be active
- ADiscordaccount with which you created everything else and that you’ll use to interact with your bot
Now, you know how to make a Discord bot using the Developer Portal. Next comes the fun stuff: implementing your bot in Python!
How to Make a Discord Bot in Python
Since you’re learning how to make a Discord bot with Python, you’ll be using discord.py.
discord.py is a Python library that exhaustively implements Discord’s APIs in an efficient and Pythonic way. This includes utilizing Python’s implementation of Async IO
Begin by installing discord.py with pip:
$ pip install -U discord.pyNow that you’ve installed discord.py, you’ll use it to create your first connection to Discord!
Creating a Discord Connection
The first step in implementing your bot user is to create a connection to Discord. With discord.py, you do this by creating an instance of Client:
# bot.py
import os
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
client = discord.Client()
@client.event
async def on_ready():
print(f'{client.user} has connected to Discord!')
client.run(TOKEN)A Client is an object that represents a connection to Discord. A Client handles events, tracks state, and generally interacts with Discord APIs.
Here, you’ve created a Client and implemented its on_ready() event handler, which handles the event when the Client has established a connection to Discord and it has finished preparing the data that Discord has sent, such as login state, guild and channel data, and more.
In other words, on_ready() will be called (and your message will be printed) once client is ready for further action. You’ll learn more about event handlers later in this article.
When you’re working with secrets such as your Discord token, it’s good practice to read it into your program from an environment variable. Using environment variables helps you:
- Avoid putting the secrets into source control
- Use different variables for development and production environments without changing your code
While you could export DISCORD_TOKEN={your-bot-token}, an easier solution is to save a .env file on all machines that will be running this code. This is not only easier, since you won’t have to export your token every time you clear your shell, but it also protects you from storing your secrets in your shell’s history.
Create a file named .env in the same directory as bot.py:
You’ll need to replace {your-bot-token} with your bot’s token, which you can get by going back to the Bot page on the Developer portal and clicking Copy under the TOKEN section:
Looking back at the bot.py code, you’ll notice a library called dotnev. This library is handy for working with .env files. load_dotenv()loads environment variables from a .env file into your shell’s environment variables so that you can use them in your code.
Install dotenv with pip:
pip install -U python-dotenvFinally, client.run() runs your Client using your bot’s token.
Now that you’ve set up both bot.py and .env, you can run your code:
python bot.py
Shikhaboat#5531 has connected to Discord!Great! Your Client has connected to Discord using your bot’s token. In the next section, you’ll build on this Client by interacting with more Discord APIs.
Interacting With Discord APIs
Using a Client, you have access to a wide range of Discord APIs.
For example, let’s say you wanted to write the name and identifier of the guild that you registered your bot user with to the console.
First, you’ll need to add a new environment variable:
# .env
DISCORD_TOKEN={your-bot-token}
DISCORD_GUILD={your-guild-name}Don’t forget that you’ll need to replace the two placeholders with actual values:
- {your-bot-token}
- {your-guild-name}
Remember that Discord calls on_ready(), which you used before, once the Client has made the connection and prepared the data. So, you can rely on the guild data being available inside on_ready():
# bot.py
import os
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
GUILD = os.getenv('DISCORD_GUILD')
client = discord.Client()
@client.event
async def on_ready():
for guild in client.guilds:
if guild.name == GUILD:
break
print(
f'{client.user} is connected to the following guild:\n'
f'{guild.name}(id: {guild.id})'
)
client.run(TOKEN)Here, you looped through the guild data that Discord has sent client, namely client.guilds. Then, you found the guild with the matching name and printed a formatted string to stdout.
Run the program to see the results:
python bot.py
Shikhaboat#5531 is connected to the following guild:
Shikhaboat#5531(id: 571759877328732195)Great! You can see the name of your bot, the name of your server, and the server’s identification number.
Another interesting bit of data you can pull from a guild is the list of users who are members of the guild:
# bot.py
import os
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
GUILD = os.getenv('DISCORD_GUILD')
client = discord.Client()
@client.event
async def on_ready():
for guild in client.guilds:
if guild.name == GUILD:
break
print(
f'{client.user} is connected to the following guild:\n'
f'{guild.name}(id: {guild.id})\n'
)
members = '\n - '.join([member.name for member in guild.members])
print(f'Guild Members:\n - {members}')
client.run(TOKEN)By looping through guild.members, you pulled the names of all of the members of the guild and printed them with a formatted string.
When you run the program, you should see at least the name of the account you created the guild with and the name of the bot user itself:
$ python bot.py
Shikhaboat#5531 is connected to the following guild:
Shikhaboat#5531(id: 571759877328732195)
Guild Members:
- aronq2
- RealPythonTutorialBotThese examples barely scratch the surface of the APIs available on Discord, be sure to check out their documentation to see all that they have to offer.
Next, you’ll learn about some utility functions and how they can simplify these examples.
Using Utility Functions
Let’s take another look at the example from the last section where you printed the name and identifier of the bot’s guild:
# bot.py
import os
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
GUILD = os.getenv('DISCORD_GUILD')
client = discord.Client()
@client.event
async def on_ready():
for guild in client.guilds:
if guild.name == GUILD:
break
print(
f'{client.user} is connected to the following guild:\n'
f'{guild.name}(id: {guild.id})'
)
client.run(TOKEN)
You could clean up this code by using some of the utility functions available in discord.py.
discord.utils.find is one utility that can improve the simplicity and readability of this code by replacing the for loop with an intuitive, abstracted function:
# bot.py
import os
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
GUILD = os.getenv('DISCORD_GUILD')
client = discord.Client()
@client.event
async def on_ready():
guild = discord.utils.find(lambda g: g.name == GUILD, client.guilds)
print(
f'{client.user} is connected to the following guild:\n'
f'{guild.name}(id: {guild.id})'
)
client.run(TOKEN)<find() takes a function, called a predicate, which identifies some characteristic of the element in the iterable that you’re looking for. Here, you used a particular type of anonymous function, called a lambda, as the predicate.
In this case, you’re trying to find the guild with the same name as the one you stored in the DISCORD_GUILD environment variable. Once find() locates an element in the iterable that satisfies the predicate, it will return the element. This is essentially equivalent to the break statement in the previous example, but cleaner.
discord.py has even abstracted this concept one step further with the get.utility():
# bot.py
import os
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
GUILD = os.getenv('DISCORD_GUILD')
client = discord.Client()
@client.event
async def on_ready():
guild = discord.utils.get(client.guilds, name=GUILD)
print(
f'{client.user} is connected to the following guild:\n'
f'{guild.name}(id: {guild.id})'
)
client.run(TOKEN)
get() takes the iterable and some keyword arguments. The keyword arguments represent attributes of the elements in the iterable that must all be satisfied for get() to return the element.
In this example, you’ve identified name=GUILD as the attribute that must be satisfied.
Now that you’ve learned the basics of interacting with APIs, you’ll dive a little deeper into the function that you’ve been using to access them: on_ready().
Responding to Events
You already learned that on_ready() is an event. In fact, you might have noticed that it is identified as such in the code by the client.event decorator.
But what is an event?
An event is something that happens on Discord that you can use to trigger a reaction in your code. Your code will listen for and then respond to events.
Using the example you’ve seen already, the on_ready() event handler handles the event that the Client has made a connection to Discord and prepared its response data.
So, when Discord fires an event, discord.py will route the event data to the corresponding event handler on your connected Client.
There are two ways in discord.py to implement an event handler:
- Using the client.event decorator
- Creating a subclass of Client and overriding its handler methods
You already saw the implementation using the decorator. Next, take a look at how to subclass Client:
# bot.py
import os
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
class CustomClient(discord.Client):
async def on_ready(self):
print(f'{self.user} has connected to Discord!')
client = CustomClient()
client.run(TOKEN)
Here, just like before, you’ve created a client variable and called <.run() with your Discord token. The actual Client is different, however. Instead of using the normal base class, client is an instance of CustomClient, which has an overridden on_ready() function.
There is no difference between the two implementation styles of events, but this tutorial will primarily use the decorator version because it looks similar to how you implement Bot commands, which is a topic you’ll cover in a bit.
Welcoming New Members
Previously, you saw the example of responding to the event where a member joins a guild. In that example, your bot user could send them a message, welcoming them to your Discord community.
Now, you’ll implement that behavior in your Client, using event handlers, and verify its behavior in Discord:
# bot.py
import os
import discord
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv('DISCORD_TOKEN')
client = discord.Client()
@client.event
async def on_ready():
print(f'{client.user.name} has connected to Discord!')
@client.event
async def on_member_join(member):
await member.create_dm()
await member.dm_channel.send(
f'Hi {member.name}, welcome to my Discord server!'
)
client.run(TOKEN)
Like before, you handled the on_ready() event by printing the bot user’s name in a formatted string. New, however, is the implementation of the on_member_join() event handler.
on_member_join(), as its name suggests, handles the event of a new member joining a guild.
In this example, you used member.create_dm()to create a direct message channel. Then, you used that channel to send() a direct message to that new member.
Now, let’s test out your bot’s new behavior.
First, run your new version of bot.py and wait for the on_ready() event to fire, logging your message to stdout:
$ python bot.py
ShikhaBot has connected to Discord!Now, head over to Discord, log in, and navigate to your guild by selecting it from the left-hand side of the screen:
Select Invite People just beside the guild list where you selected your guild. Check the box that says Set this link to never expire and copy the link:
Now, with the invite link copied, create a new account and join the guild using your invite link.
First, you’ll see that Discord introduced you to the guild by default with an automated message. More importantly though, notice the badge on the left-hand side of the screen that notifies you of a new message:
When you select it, you’ll see a private message from your bot user:
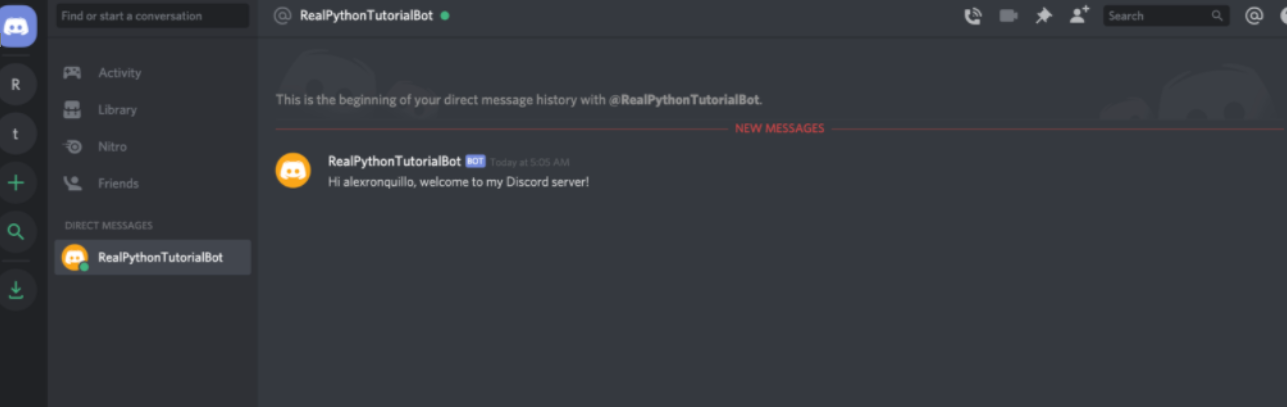
Perfect! Your bot user is now interacting with other users with minimal code.
Conclusion
Congratulations! Now, you’ve learned how to make a Discord bot in Python. You’re able to build bots for interacting with users in guilds that you create or even bots that other users can invite to interact with their communities.