
In this tutorial, we will discuss the different methods to display full Dataframe i.e. print all rows & columns without truncation. So, get into this page and learn completely about Pandas dataframe in python i.e. how to print all rows & columns without truncation. Also, you can get a clear idea of how to display full dataframe from here. Pandas will be displayed column in the full dataframe.
- Display Full Contents of a Dataframe
- How to print an entire Pandas DataFrame in Python?
- Four Methods to Print the entire pandas Dataframe
- Use to_string() Method
- Use pd.option_context() Method
- Use pd.set_options() Method
- Use pd.to_markdown() Method
Display Full Contents of a Dataframe
Pandas implement an operating system to customize the behavior & display similar stuff. By applying this benefits module we can configure the display to show the complete dataframe rather than a truncated one. A function set_option()is provided in pandas to set this kind of option,
pandas.set_option(pat, value)
It sets the value of the defined option. Let’s use this to display the full contents of a dataframe.
Setting to display All rows of Dataframe
In pandas when we print a dataframe, it displays at max_rows number of rows. If we have more rows, then it truncates the rows.
pandas.options.display.max_rows
This option outlines the maximum number of rows that pandas will present while printing a dataframe. The default value of max_rows is 10.
In case, it is set to ‘None‘ then it implies unlimited i.e. pandas will display all the rows in the dataframe. Let’s set it to None while printing the contents of above-created dataframe empDfObj,
# Default value of display.max_rows is 10 i.e. at max 10 rows will be printed.
# Set it None to display all rows in the dataframe
pd.set_option('display.max_rows', None)Let’s examine the contents of the dataframe again,
print(empDfObj)
Output:
A B ... Z AA 0 jack 34 ... 122 111 1 Riti 31 ... 222 211 2 Aadi 16 ... 322 311 3 Sunil 41 ... 422 411 4 Veena 33 ... 522 511 5 Shaunak 35 ... 622 611 6 Shaun 35 ... 722 711 7 jack 34 ... 122 111 8 Riti 31 ... 222 211 9 Aadi 16 ... 322 311 10 Sunil 41 ... 422 411 11 Veena 33 ... 522 511 12 Shaunak 35 ... 622 611 13 Shaun 35 ... 722 711 14 jack 34 ... 122 111 15 Riti 31 ... 222 211 16 Aadi 16 ... 322 311 17 Sunil 41 ... 422 411 18 Veena 33 ... 522 511 19 Shaunak 35 ... 622 611 20 Shaun 35 ... 722 711 21 jack 34 ... 122 111 22 Riti 31 ... 222 211 23 Aadi 16 ... 322 311 24 Sunil 41 ... 422 411 25 Veena 33 ... 522 511 26 Shaunak 35 ... 622 611 27 Shaun 35 ... 722 711 28 jack 34 ... 122 111 29 Riti 31 ... 222 211 30 Aadi 16 ... 322 311 31 Sunil 41 ... 422 411 32 Veena 33 ... 522 511 33 Shaunak 35 ... 622 611 34 Shaun 35 ... 722 711 35 jack 34 ... 122 111 36 Riti 31 ... 222 211 37 Aadi 16 ... 322 311 38 Sunil 41 ... 422 411 39 Veena 33 ... 522 511 40 Shaunak 35 ... 622 611 41 Shaun 35 ... 722 711 42 jack 34 ... 122 111 43 Riti 31 ... 222 211 44 Aadi 16 ... 322 311 45 Sunil 41 ... 422 411 46 Veena 33 ... 522 511 47 Shaunak 35 ... 622 611 48 Shaun 35 ... 722 711 49 jack 34 ... 122 111 50 Riti 31 ... 222 211 51 Aadi 16 ... 322 311 52 Sunil 41 ... 422 411 53 Veena 33 ... 522 511 54 Shaunak 35 ... 622 611 55 Shaun 35 ... 722 711 56 jack 34 ... 122 111 57 Riti 31 ... 222 211 58 Aadi 16 ... 322 311 59 Sunil 41 ... 422 411 60 Veena 33 ... 522 511 61 Shaunak 35 ... 622 611 62 Shaun 35 ... 722 711 [63 rows x 27 columns]
Also Check:
How to print an entire Pandas DataFrame in Python?
When we use a print large number of a dataset then it truncates. In this article, we are going to see how to print the entire pandas Dataframe or Series without Truncation.
The complete data frame is not printed when the length exceeds.
import numpy as np from sklearn.datasets import load_iris import pandas as pd # Loading irirs dataset data = load_iris() df = pd.DataFrame(data.data,columns = data.feature_names) print(df)
Output:
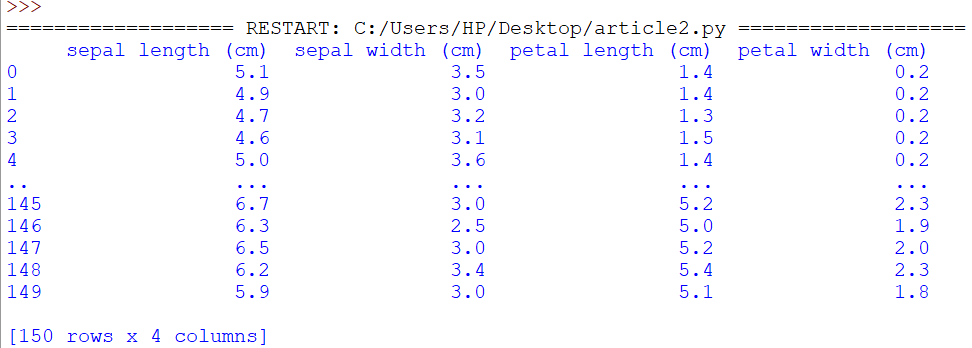
By default our complete contents of out dataframe are not printed, output got truncated. It printed only 10 rows all the remaining data is truncated. Now, what if we want to print the full dataframe without any truncation.
Four Methods to Print the entire pandas Dataframe
- Use to_string() Method
- Use pd.option_context() Method
- Use pd.set_options() Method
- Use pd.to_markdown() Method
1. Using to_string()
This is a very simple method. That is why it is not used for large files because it converts the entire data frame into a string object. But this works very well for data frames for size in the order of thousands.
import numpy as np
from sklearn.datasets import load_iris
import pandas as pd
data = load_iris()
df = pd.DataFrame(data.data,
columns = data.feature_names)
# Convert the whole dataframe as a string and display
print(df.to_string())
Output:
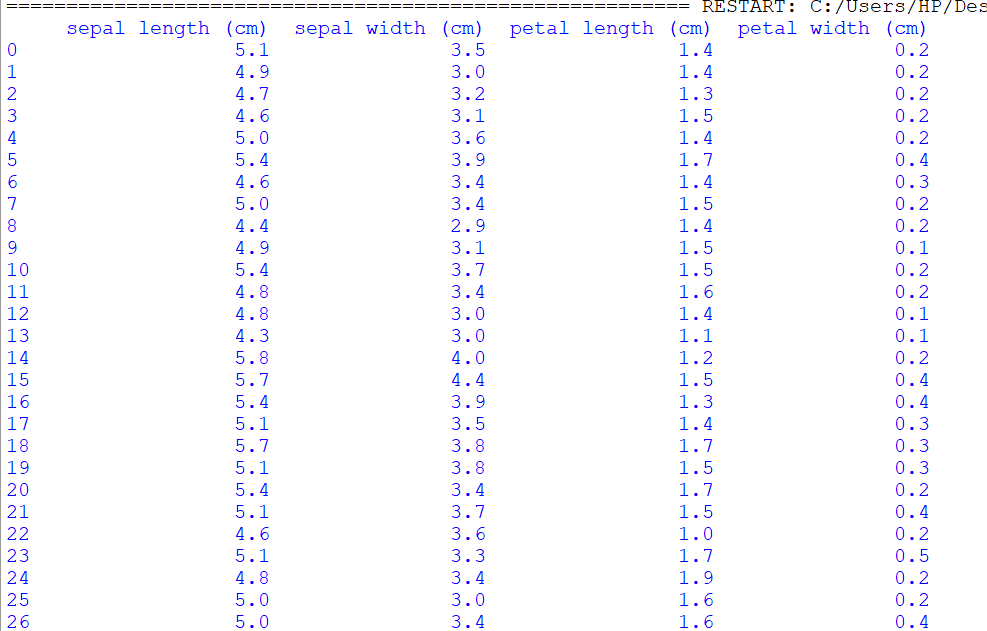
So in the above example, you have seen it printed all columns without any truncation.
2. Using pd.option_context()
option_context() and set_option() both methods are identical but there is only one difference that is one changes the settings and the other do it only within the context manager scope.
import numpy as np
from sklearn.datasets import load_iris
import pandas as pd
data = load_iris()
df = pd.DataFrame(data.data,
columns = data.feature_names)
with pd.option_context('display.max_rows', None,'display.max_columns', None,
'display.precision', 3,
):
print(df)Output:
In the above example, we are used ‘display.max_rows‘ but by default its value is 10 & if the dataframe has more rows it will truncate. So it will not be truncated we used None so all the rows are displayed.
3. Using pd.set_option()
This method is similar to pd.option_context() method and takes the same parameters. pd.reset_option(‘all’) used to reset all the changes.
import numpy as np
from sklearn.datasets import load_iris
import pandas as pd
data = load_iris()
df = pd.DataFrame(data.data,
columns = data.feature_names)
# Permanently changes the pandas settings
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.width', None)
pd.set_option('display.max_colwidth', -1)
# All dataframes hereafter reflect these changes.
print(df)
print('**RESET_OPTIONS**')
# Resets the options
pd.reset_option('all')
print(df)
Output:
**RESET_OPTIONS** : boolean use_inf_as_null had been deprecated and will be removed in a future version. Use `use_inf_as_na` instead.
4. Using to_markdown()
This method is similar to the to_string() method as it also converts the data frame to a string object and also adds styling & formatting to it.
import numpy as np
from sklearn.datasets import load_iris
import pandas as pd
data = load_iris()
df = pd.DataFrame(data.data,
columns=data.feature_names)
# Converts the dataframe into str object with fromatting
print(df.to_markdown())Output:
Want to expert in the python programming language? Exploring Python Data Analysis using Pandas tutorial changes your knowledge from basic to advance level in python concepts.
Read more Articles on Python Data Analysis Using Padas
- How to merge Dataframes using Dataframe.merge() in Python?
- How to merge Dataframes on specific columns or on index in Python?
- How to merge Dataframes by index using Dataframe.merge()?
- Count NaN or missing values in DataFrame
- Count rows in a dataframe | all or those only that satisfy a condition
- 6 Different ways to iterate over rows in a Dataframe & Update while iterating row by row
- Loop or Iterate over all or certain columns of a DataFrame