What is RSS?
RSS stands for Really Simple Syndication or Rich Site Summary. It is a type of web feed that allows users and applications to receive regular updates from a website or blog of their choice. Various website use their RSS feed to publish the frequently updated information like blog entries, news headlines etc, So this is where RSS feeds are mainly used.
So we can use that RSS feed to extract some important information from a particular website. In this article I will be showing how you will extract RSS feeds of any website.
Installing packages
You can install all packages using pip like the example below.
pip install requests pip install bs4
Importing libraries:
Now our project setup is ready, we can start writing the code.
Within our rssScrapy.py we’ll import the packages we’ve installed using pip.
import requests from bs4 import BeautifulSoup
The above package will allow us to use the functions given to us by the Requests and BeautifulSoup libraries.
I am going to use the RSS feeds of a news website called Times of India.
Link-"https://timesofindia.indiatimes.com/rssfeeds/1221656.cms"
This is basically an XML file.
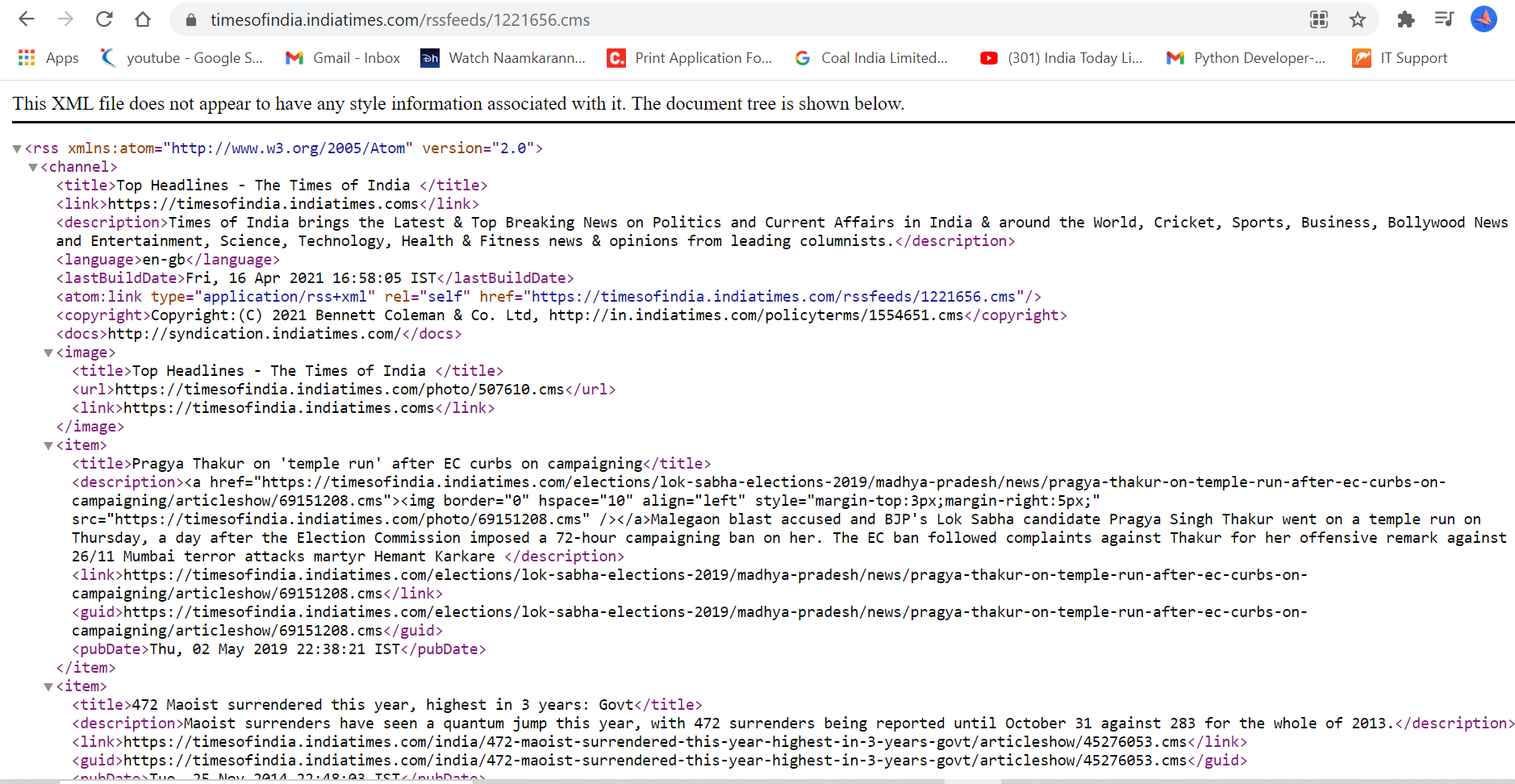
So now I am going to show you how this particular xml file will scrape.
import requests from bs4 import BeautifulSoup url="https://timesofindia.indiatimes.com/rssfeeds/1221656.cms" resp=requests.get(url) soup=BeautifulSoup(resp.content,features="xml") print(soup.prettify())
I have imported all necessary libraries.I have also defined url which give me link for news website RSS feed after that for get request I made resp object where I have pass that url.
Now we have response object and we have also a beautiful soup object with me.Bydefault beautiful soup parse html file but we want xml file so we used features=”xml”.So now let me just show you the xml file we have parsed.
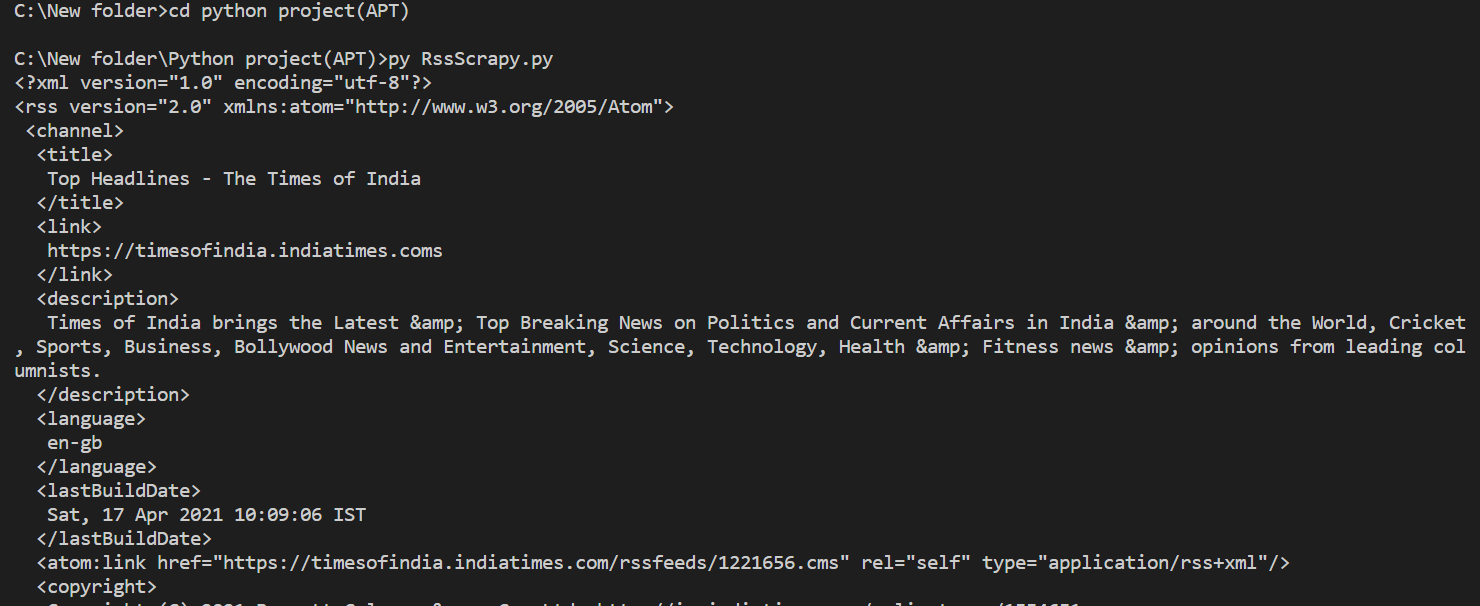
We dont nedd all the data having in it.We want news description,title,publish date right.So for this we are going to create a list which contains all the content inside item tags.For this we have used items=soup.findAll('item')
You can also check the length of items using this len(items)
So now I am writing whole code for scrapping the news RSS feed-
import requests
from bs4 import BeautifulSoup
url="https://timesofindia.indiatimes.com/rssfeeds/1221656.cms"
resp=requests.get(url)
soup=BeautifulSoup(resp.content,features="xml")
items=soup.findAll('item')
item=items[0]
news_items=[]
for item in items:
news_item={}
news_item['title']=item.title.text
news_item['description']=item.description.text
news_item['link']=item.link.text
news_item['guid']=item.guid.text
news_item['pubDate']=item.pubDate.text
news_items.append(news_item)
print(news_items[2])So we can see that I have used item.title.textfor scrapping title because item is parent class and title is child class similarly we do for rest.
Each of the articles available on the RSS feed containing all information within item tags <item>...</item>.
and follows the below structure-
<item>
<title>...</title>
<link>...</link>
<pubDate>...</pubDate>
<comments>...</comments>
<description>...</description>
</item>We’ll be taking advantage of the consistent item tags to parse our information.
I have also make an empty list news_items which append all in it.
So this is how we can parse particularly news item.

Conclusion:
We have successfully created an RSS feed scraping tool using Python, Requests, and BeautifulSoup. This allows us to parse XML information into a suitable format for us to work with in the future.