In this article, we will discuss the replacement of NaN values with a mean of the values in rows and columns using two functions: fillna() and mean().
In data analytics, we have a large dataset in which values are missing and we have to fill those values to continue the analysis more accurately.
Python provides the built-in methods to rectify the NaN values or missing values for cleaner data set.
These functions are:
Dataframe.fillna():
This method is used to replace the NaN in the data frame.
The mean() method:
mean(axis=None, skipna=None, level=None, numeric_only=None, **kwargs)
Parameters::
- Axis is the parameter on which the function will be applied. It denotes a boolean value for rows and column.
- Skipna excludes the null values when computing the results.
- If the axis is a MultiIndex (hierarchical), count along with a particular level, collapsing into a Series.
- Numeric_only will use the numeric values when None is there.
- **kwargs: Additional keyword arguments to be passed to the function.
This function returns the mean of the values.
Let’s dig in deeper to get a thorough understanding!
Pandas: Replace NaN with column mean
We can replace the NaN values in the whole dataset or just in a column by getting the mean values of the column.
For instance, we will take a dataset that has the information about 4 students S1 to S4 with marks in different subjects.
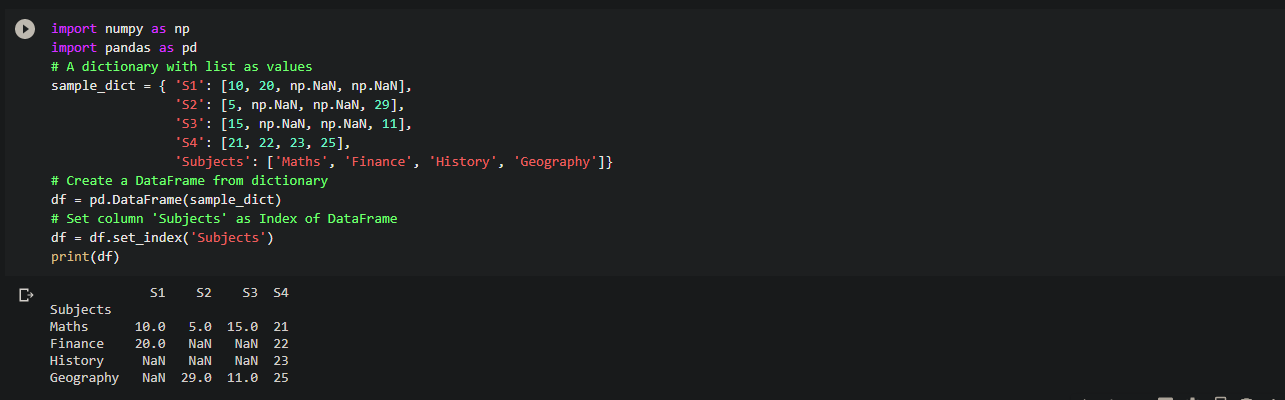
Code:
Suppose we have to calculate the mean value of S2 columns, then we will see that a single value of float type is returned.

Code:
Replace NaN values in a column with mean of column values
Let’s see how to replace the NaN values in column S2 with the mean of column values.

Code:
df['S2'].fillna(value=df['S2'].mean(), inplace=True) print('Updated Dataframe:') print(df)
We can see that the mean() method is called by the S2 column, therefore the value argument had the mean of column values. So the NaN values are replaced with the mean values.
Replace all NaN values in a Dataframe with mean of column values
Now, we will see how to replace all the NaN values in a data frame with the mean of S2 columns values.
We can simply apply the fillna() function with the entire data frame instead of a particular column.

Code:
df.fillna(value=df['S2'].mean(), inplace=True) print('Updated Dataframe:') print(df)
We can see that all the values got replaced with the mean value of the S2 column. The inplace = True has been assigned to make the permanent change.
Pandas: Replace NANs with mean of multiple columns
We will reinitialize our data frame with NaN values.

Code:
df = pd.DataFrame(sample_dict) # Set column 'Subjects' as Index of DataFrame df = df.set_index('Subjects') # Dataframe with NaNs print(df)
If we want to make changes to multiple columns then we will mention multiple columns while calling the mean() functions.

Code:
mean_values=df[['S2','S3']].mean() print(mean_values)
It returned the calculated mean of two columns that are S2 and the S3.
Now, we will replace the NaN values in columns S2 and S3 with the mean values of these columns.

Code:
df[['S2','S3']] = df[['S2','S3']].fillna(value=df[['S2','S3']].mean()) print('Updated Dataframe:') print(df)
Pandas: Replace NANs with row mean
We can apply the same method as we have done above with the row. Previously, we replaced the NaN values with the mean of the columns but here we will replace the NaN values in the row by calculating the mean of the row.
For this, we need to use .loc(‘index name’) to access a row and then use fillna() and mean() methods.

Code:
df.loc['History'] = df.loc['History'].fillna(value=df.loc['History'].mean()) print('Updated Dataframe:') print(df)
Conclusion
So, these were different ways to replace NaN values in a column, row or complete data frame with mean or average values.
Hope this article was useful for you!