Python: Read a CSV file line by line with or without header
In this article, we will be learning about how to read a CSV file line by line with or without a header. Along with that, we will be learning how to select a specified column while iterating over a file.
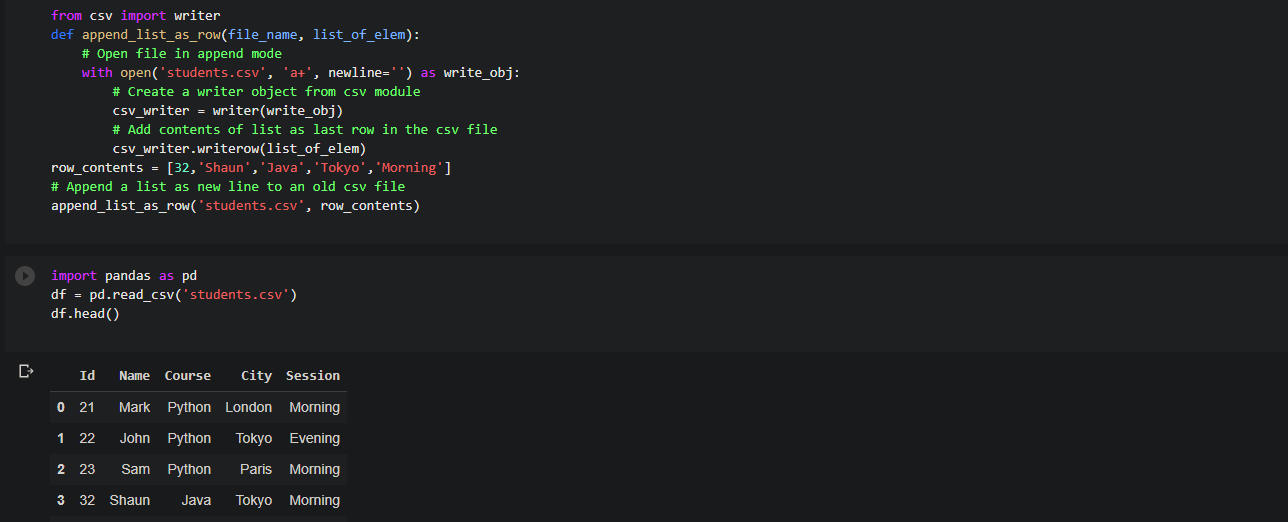
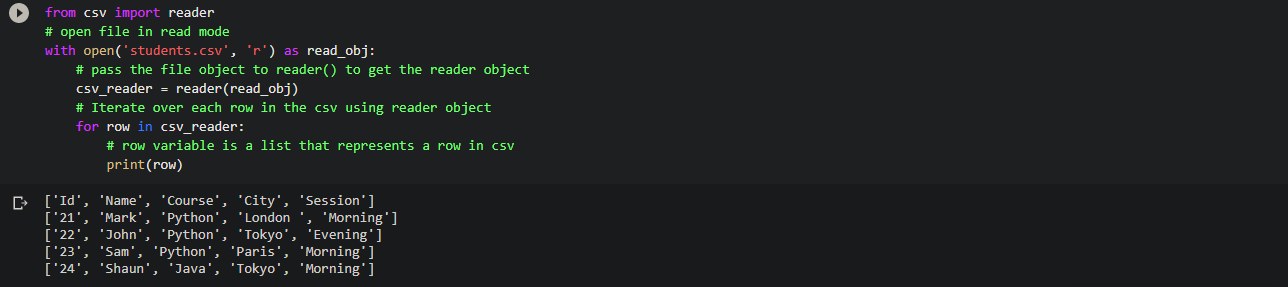
Let us take an example where we have a file named students.csv.
Id,Name,Course,City,Session 21,Mark,Python,London,Morning 22,John,Python,Tokyo,Evening 23,Sam,Python,Paris,Morning 32,Shaun,Java,Tokyo,Morning
Read a CSV file line by line using csv.reader
By using the csv.reader module, a reader class object is made through which we can iterate over the lines of a CSV file as a list of values, where each value in the list is a cell value.
Code:
from csv import reader # open file in read mode with open('students.csv', 'r') as read_obj: # pass the file object to reader() to get the reader object csv_reader = reader(read_obj) # Iterate over each row in the csv using reader object for row in csv_reader: # row variable is a list that represents a row in csv print(row)
How did it work?
It performed a few steps:
- Opened the students.csv file and created a file object.
- In csv.reader() function, the reader object is created and passed.
- Now with the reader object, we iterated it by using the for loop so that it can read each row of the csv as a list of values.
- At last, we printed this list.
By using this module, only one line will consume memory at a time while iterating through a csv file.
Read csv file without header
What if we want to skip a header and print the files without the header. In the previous example, we printed the values including the header but in this example, we will remove the header and print the values without the header.
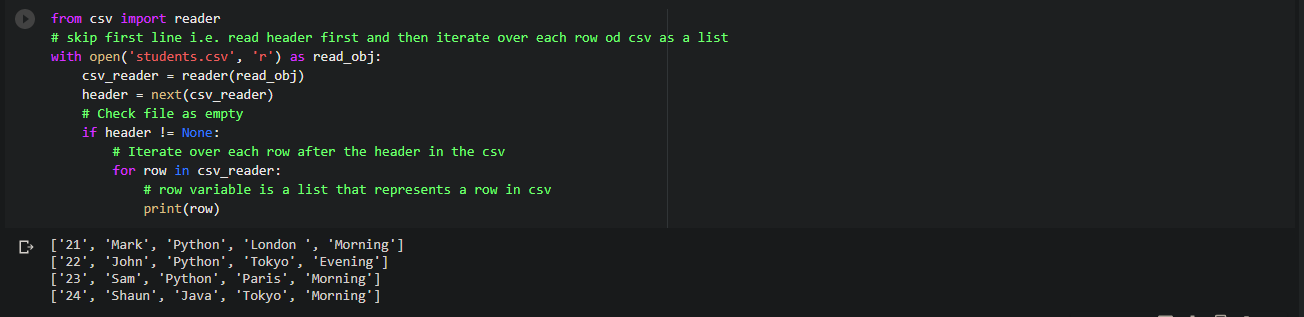
Code:
from csv import reader # skip first line i.e. read header first and then iterate over each row od csv as a list with open('students.csv', 'r') as read_obj: csv_reader = reader(read_obj) header = next(csv_reader) # Check file as empty if header != None: # Iterate over each row after the header in the csv for row in csv_reader: # row variable is a list that represents a row in csv print(row)
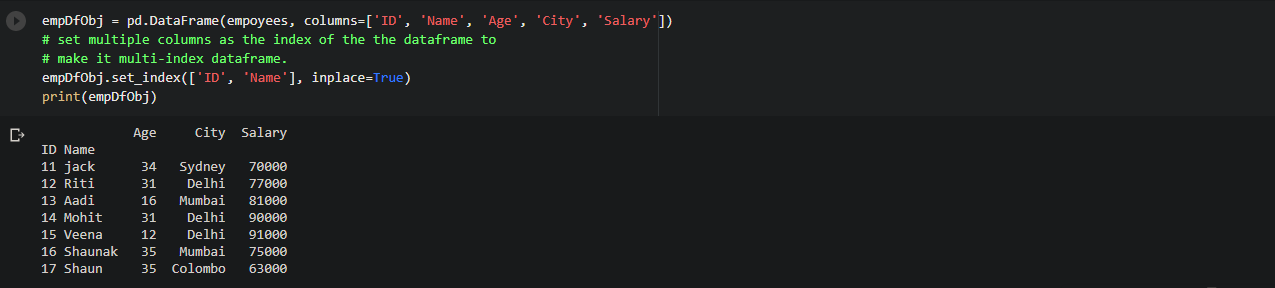
Read csv file line by line using csv module DictReader object
Now, we will see the example using csv.DictReader module. CSV’s module dictReader object class iterates over the lines of a CSV file as a dictionary, which means for each row it returns a dictionary containing the pair of column names and values for that row.
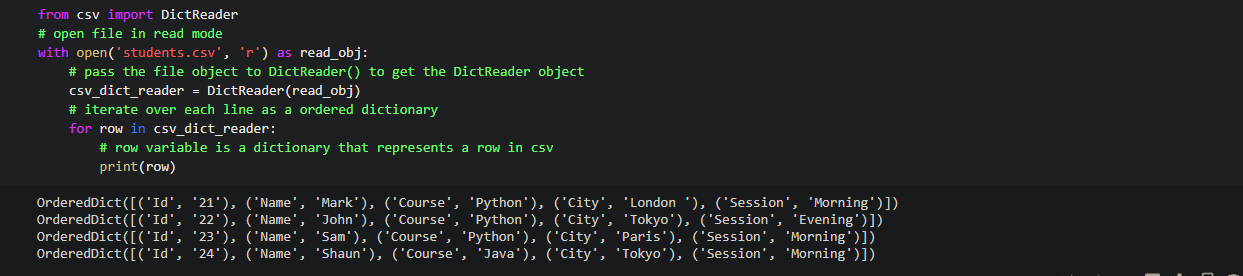
Code:
from csv import DictReader # open file in read mode with open('students.csv', 'r') as read_obj: # pass the file object to DictReader() to get the DictReader object csv_dict_reader = DictReader(read_obj) # iterate over each line as a ordered dictionary for row in csv_dict_reader: # row variable is a dictionary that represents a row in csv print(row)
How did it work?
It performed a few steps:
- Opened the students.csv file and created a file object.
- In csv.DictReader() function, the reader object is created and passed.
- Now with the reader object, we iterated it by using the for loop so that it can read each row of the csv as a dictionary of values. Where each pair in this dictionary represents contains the column name & column value for that row.
It also saves the memory as only one row at a time is in the memory.
Get column names from the header in the CSV file
We have a member function in the DictReader class that returns the column names of a csv file as a list.
 Code:
Code:
Read specific columns from a csv file while iterating line by line
Read specific columns (by column name) in a CSV file while iterating row by row

from csv import DictReader # iterate over each line as a ordered dictionary and print only few column by column name withopen('students.csv', 'r')as read_obj: csv_dict_reader = DictReader(read_obj) for row in csv_dict_reader: print(row['Id'], row['Name'])
Read specific columns (by column Number) in a CSV file while iterating row by row
We will iterate over all the rows of the CSV file line by line but will print the contents of the 2nd and 3rd column.
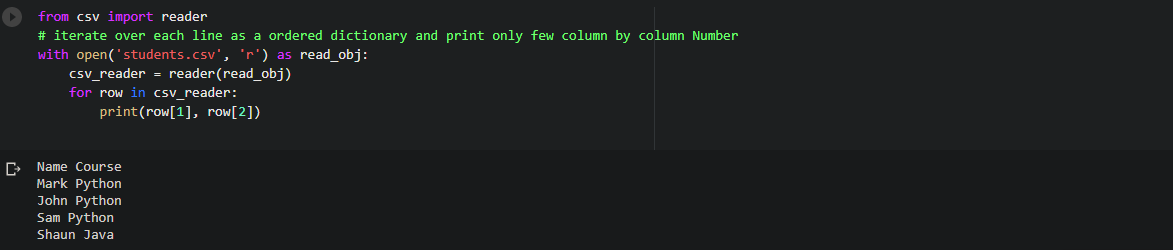
Code:
from csv import reader # iterate over each line as a ordered dictionary and print only few column by column Number with open('students.csv', 'r') as read_obj: csv_reader = reader(read_obj) for row in csv_reader: print(row[1], row[2])
from csv import reader from csv import DictReader def main(): print('*** Read csv file line by line using csv module reader object ***') print('*** Iterate over each row of a csv file as list using reader object ***') # open file in read mode with open('students.csv', 'r') as read_obj: # pass the file object to reader() to get the reader object csv_reader = reader(read_obj) # Iterate over each row in the csv using reader object for row in csv_reader: # row variable is a list that represents a row in csv print(row) print('*** Read csv line by line without header ***') # skip first line i.e. read header first and then iterate over each row od csv as a list with open('students.csv', 'r') as read_obj: csv_reader = reader(read_obj) header = next(csv_reader) # Check file as empty if header != None: # Iterate over each row after the header in the csv for row in csv_reader: # row variable is a list that represents a row in csv print(row) print('Header was: ') print(header) print('*** Read csv file line by line using csv module DictReader object ***') # open file in read mode with open('students.csv', 'r') as read_obj: # pass the file object to DictReader() to get the DictReader object csv_dict_reader = DictReader(read_obj) # iterate over each line as a ordered dictionary for row in csv_dict_reader: # row variable is a dictionary that represents a row in csv print(row) print('*** select elements by column name while reading csv file line by line ***') # open file in read mode with open('students.csv', 'r') as read_obj: # pass the file object to DictReader() to get the DictReader object csv_dict_reader = DictReader(read_obj) # iterate over each line as a ordered dictionary for row in csv_dict_reader: # row variable is a dictionary that represents a row in csv print(row['Name'], ' is from ' , row['City'] , ' and he is studying ', row['Course']) print('*** Get column names from header in csv file ***') # open file in read mode with open('students.csv', 'r') as read_obj: # pass the file object to DictReader() to get the DictReader object csv_dict_reader = DictReader(read_obj) # get column names from a csv file column_names = csv_dict_reader.fieldnames print(column_names) print('*** Read specific columns from a csv file while iterating line by line ***') print('*** Read specific columns (by column name) in a csv file while iterating row by row ***') # iterate over each line as a ordered dictionary and print only few column by column name with open('students.csv', 'r') as read_obj: csv_dict_reader = DictReader(read_obj) for row in csv_dict_reader: print(row['Id'], row['Name']) print('*** Read specific columns (by column Number) in a csv file while iterating row by row ***') # iterate over each line as a ordered dictionary and print only few column by column Number with open('students.csv', 'r') as read_obj: csv_reader = reader(read_obj) for row in csv_reader: print(row[1], row[2]) if __name__ == '__main__': main()
I hope you understood this article as well as the code.
Happy reading!
Python: Read a CSV file line by line with or without header Read More »