In this article, we will be checking up few things:
- Basic crawling setup In Python
- Basic crawling with AsyncIO
- Scraper Util service
- Python scraping via Scrapy framework
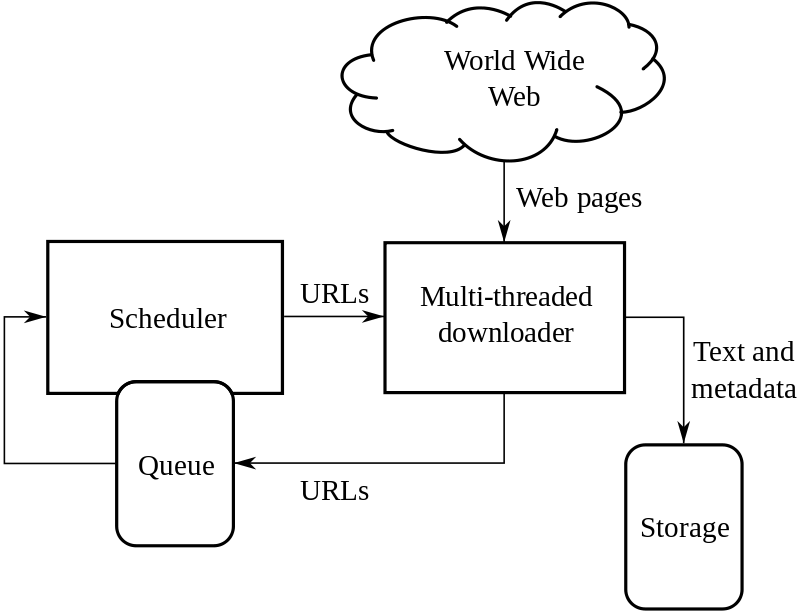
Web Crawler
A web crawler is an automatic bot that extracts useful information by systematically browsing the world wide web.
The web crawler is also known as a spider or spider bot. Some websites use web crawling for updating their web content. Some websites do not allow crawling because of their security, so on that websites crawler works by either asking for permission or exiting out of the website.
Web Scraping
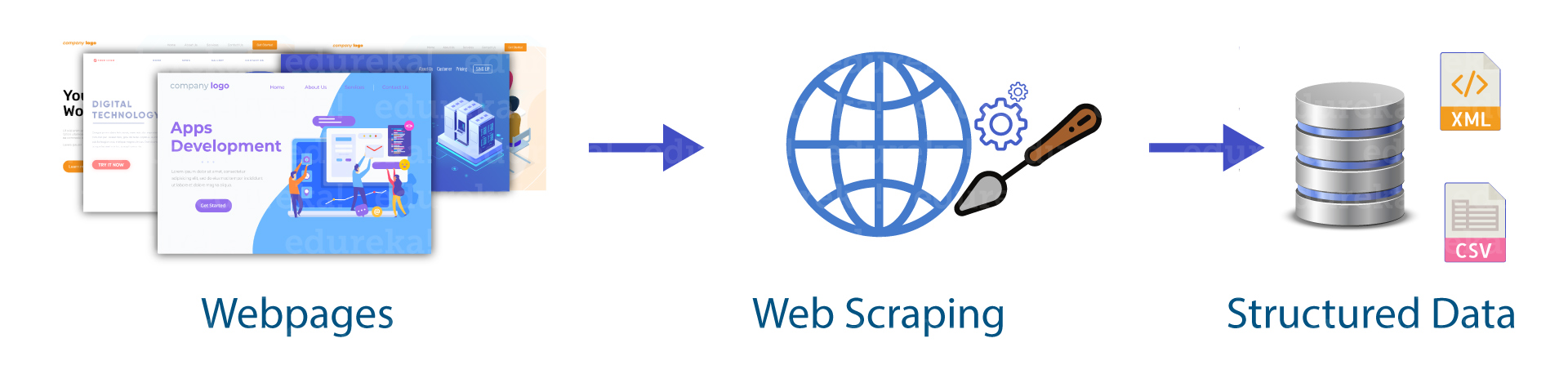
Extracting the data from the websites is known as web scraping. Web scraping requires two parts crawler and scraper.
Crawler is known to be an artificial intelligence algorithm and it browses the web which leads to searching of the links we want to crawl across the internet.
Scraper is the tool that was specifically used for extracting information from the internet.
By web scraping, we can obtain a large amount of data which is in unstructured data in an HTML format and then it is converted into structured data.
Crawler Demo
Mainly, we have been using two tools:
- Python request module to make a crawler bot. We can get it from (https://pypi.org/project/requests/)
- Parsel Library which is used as a scraping tool. Access it from (https://parsel.readthedocs.io/en/latest/usage.html)
Task I
Scrap recurship website is used for extracting all the links and images present on the page.
Demo Code:
Import requests
from parsel import Selector
import time
start = time.time()
response = requests.get('http://recurship.com/')
selector = Selector(response.text)
href_links = selector.xpath('//a/@href').getall()
image_links = selector.xpath('//img/@src').getall()
print("********************href_links****************")
print(href_links)
print("******************image_links****************")
print(image_links)
end = time.time()
print("Time taken in seconds:", (end_start)
Task II
Scrap recurship site and extract links, one of one navigate to each link and extract information of the images.
Demo code:
import requests
from parsel import Selector
import time
start = time.time()
all_images = {}
response = requests.get('http://recurship.com/')
selector = Selector(response.text)
href_links = selector.xpath('//a/@href').getall()
image_links = selector.xpath('//img/@src').getall()
for link in href_links:
try:
response = requests.get(link)
if response.status_code == 200:
image_links = selector.xpath('//img/@src').getall()
all_images[link] = image_links
except Exception as exp:
print('Error navigating to link : ', link)
print(all_images)
end = time.time()
print("Time taken in seconds : ", (end-start))
Task II takes 22 seconds to complete. We are constantly using the python “parsel” and “request” package.
Let’s see some features these packages use.
Request package:
Python request module basically offers the following features:
- HTTP method calls
- Working with response codes and headers
- Maintains redirection and history for requests
- Maintains sessions
- Work with cookies
- Errors and exceptions
Parsel package
Python parsel package offers the following features:
- Extract text using CSS or XPath selectors
- Regular expression helper methods
Crawler service using Request and Parsel
The code:
import requests
import time
import random
from urllib.parse import urlparse
import logging
logger = logging.getLogger(__name__)
LOG_PREFIX = 'RequestManager:'
class RequestManager:
def __init__(self):
self.set_user_agents(); # This is to keep user-agent same throught out one request
crawler_name = None
session = requests.session()
# This is for agent spoofing...
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.246',
'Mozilla/4.0 (X11; Linux x86_64) AppleWebKit/567.36 (KHTML, like Gecko) Chrome/62.0.3239.108 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko'
]
headers = {}
cookie = None
debug = True
def file_name(self, context: RequestContext, response, request_type: str = 'GET'):
url = urlparse(response.url).path.replace("/", "|")
return f'{time.time()}_{context.get("key")}_{context.get("category")}_{request_type}_{response.status_code}_{url}'
# write a file, safely
def write(self, name, text):
if self.debug:
file = open(f'logs/{name}.html', 'w')
file.write(text)
file.close()
def set_user_agents(self):
self.headers.update({
'user-agent': random.choice(self.user_agents)
})
def set_headers(self, headers):
logger.info(f'{LOG_PREFIX}:SETHEADER set headers {self.headers}')
self.session.headers.update(headers)
def get(self, url: str, withCookie: bool = False, context):
logger.info(f'{LOG_PREFIX}-{self.crawler_name}:GET making get request {url} {context} {withCookie}')
cookies = self.cookie if withCookie else None
response = self.session.get(url=url, cookies=cookies, headers=self.headers)
self.write(self.file_name(context, response), response.text)
return response
def post(self, url: str, data, withCookie: bool = False, allow_redirects=True, context: RequestContext = {}):
logger.info(f'{LOG_PREFIX}:POST making post request {url} {data} {context} {withCookie}')
cookies = self.cookie if withCookie else None
response = self.session.post(url=url, data=data, cookies=cookies, allow_redirects=allow_redirects)
self.write(self.file_name(context, response, request_type='POST'), response.text)
return response
def set_cookie(self, cookie):
self.cookie = cookie
logger.info(f'{LOG_PREFIX}-{self.crawler_name}:SET_COOKIE set cookie {self.cookie}')
Request = RequestManager()
context = {
"key": "demo",
"category": "history"
}
START_URI = "DUMMY_URL" # URL OF SIGNUP PORTAL
LOGIN_API = "DUMMY_LOGIN_API"
response = Request.get(url=START_URI, context=context)
Request.set_cookie('SOME_DUMMY_COOKIE')
Request.set_headers('DUMMY_HEADERS')
response = Request.post(url=LOGIN_API, data = {'username': '', 'passphrase': ''}, context=context)
Class “RequestManager” offers few functionalities listed below:
- POST and GET calls with logging
- Saving responses as log files of each HTTP request
- Setting headers and cookies
- Session management
- Agent spoofing
Scraping with AsyncIO
All we have to do is scrap the Recurship site and extract all the links, later we navigate each link asynchronously and extract information from the images.
Demo code
import requests
import aiohttp
import asyncio
from parsel import Selector
import time
start = time.time()
all_images = {} # website links as "keys" and images link as "values"
async def fetch(session, url):
try:
async with session.get(url) as response:
return await response.text()
except Exception as exp:
return '<html> <html>' #empty html for invalid uri case
async def main(urls):
tasks = []
async with aiohttp.ClientSession() as session:
for url in urls:
tasks.append(fetch(session, url))
htmls = await asyncio.gather(*tasks)
for index, html in enumerate(htmls):
selector = Selector(html)
image_links = selector.xpath('//img/@src').getall()
all_images[urls[index]] = image_links
print('*** all images : ', all_images)
response = requests.get('http://recurship.com/')
selector = Selector(response.text)
href_links = selector.xpath('//a/@href').getall()
loop = asyncio.get_event_loop()
loop.run_until_complete(main(href_links))
print ("All done !")
end = time.time()
print("Time taken in seconds : ", (end-start))By AsyncIO, scraping took almost 21 seconds. We can achieve more good performance with this task.
Open-Source Python Frameworks for spiders
Python has multiple frameworks which take care of the optimization
It gives us different patterns. There are three popular frameworks, namely:
- Scrapy
- PySpider
- Mechanical soup
Let’s use Scrapy for further demo.
Scrapy
Scrapy is a framework used for scraping and is supported by an active community. We can build our own scraping tools.
There are few features which scrapy provides:
- Scraping and parsing tools
- Easily export the data it collects in a number of formats like JSON or CSV and store the data on a backend of your choosing
- Has a number of built-in extensions for tasks like cookie handling, user-agent spoofing, restricting crawl depth, and others
- Has an API for easily building your own additions.
- Scrapy also offers a cloud to host spiders where spiders scale on-demand and run from thousand to billions. It’s like Heroku of spiders.
Now we have to do is scrap the Recurship site and extract all the links, later we navigate each link asynchronously and extract information from the images.
Demo Code
import scrapy
class AuthorSpider(scrapy.Spider):
name = 'Links'
start_urls = ['http://recurship.com/']
images_data = {}
def parse(self, response):
# follow links to author pages
for img in response.css('a::attr(href)'):
yield response.follow(img, self.parse_images)
# Below commented portion is for following all pages
# follow pagination links
# for href in response.css('a::attr(href)'):
# yield response.follow(href, self.parse)
def parse_images(self, response):
#print "URL: " + response.request.url
def extract_with_css(query):
return response.css(query).extract()
yield {
'URL': response.request.url,
'image_link': extract_with_css('img::attr(src)')
}Commands
scrapy run spider -o output.json spider.py
The JSON file got export in 1 second.
Conclusion
We can see that the scrapy performed an excellent job. If we have to perform simple crawling, scrapy will give the best results.
Enjoy scraping!!