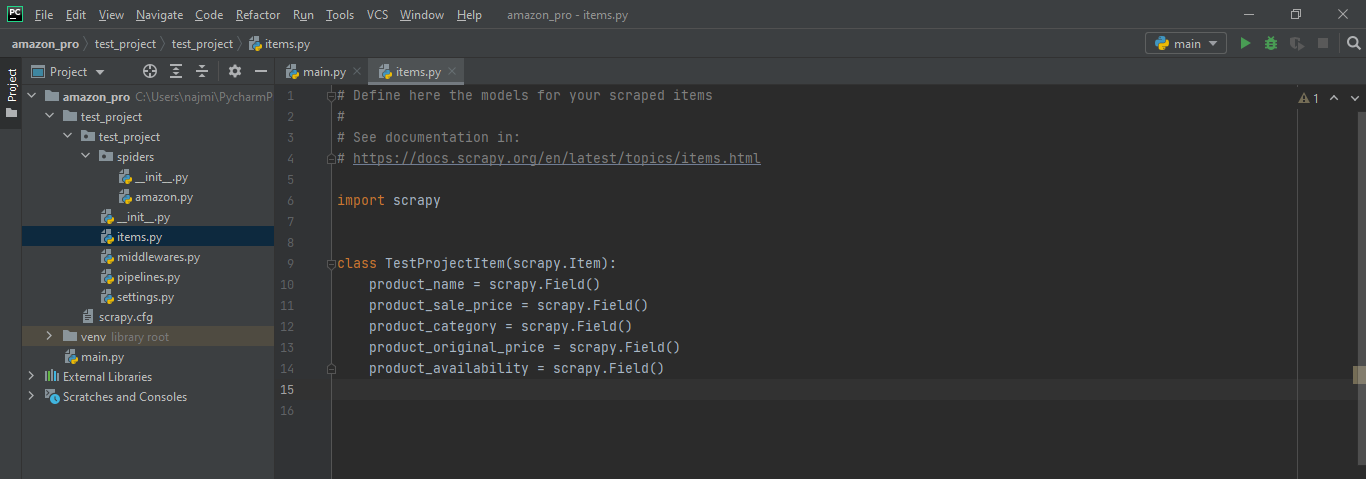
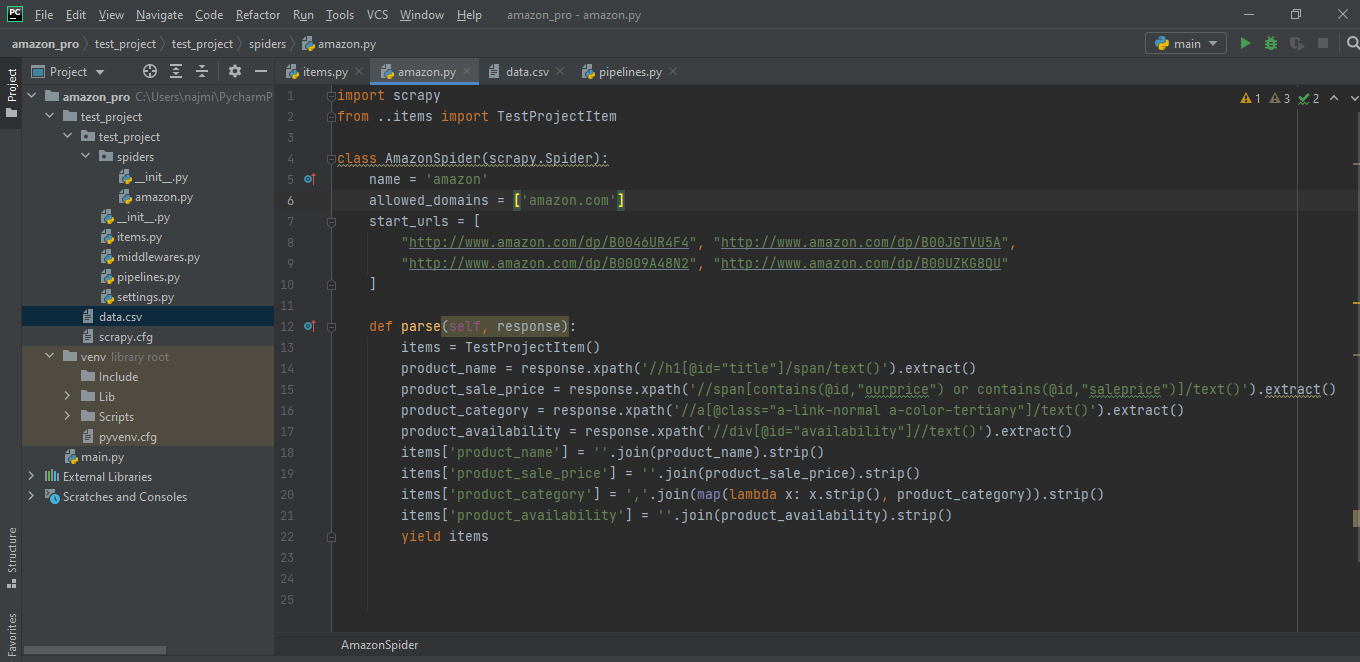
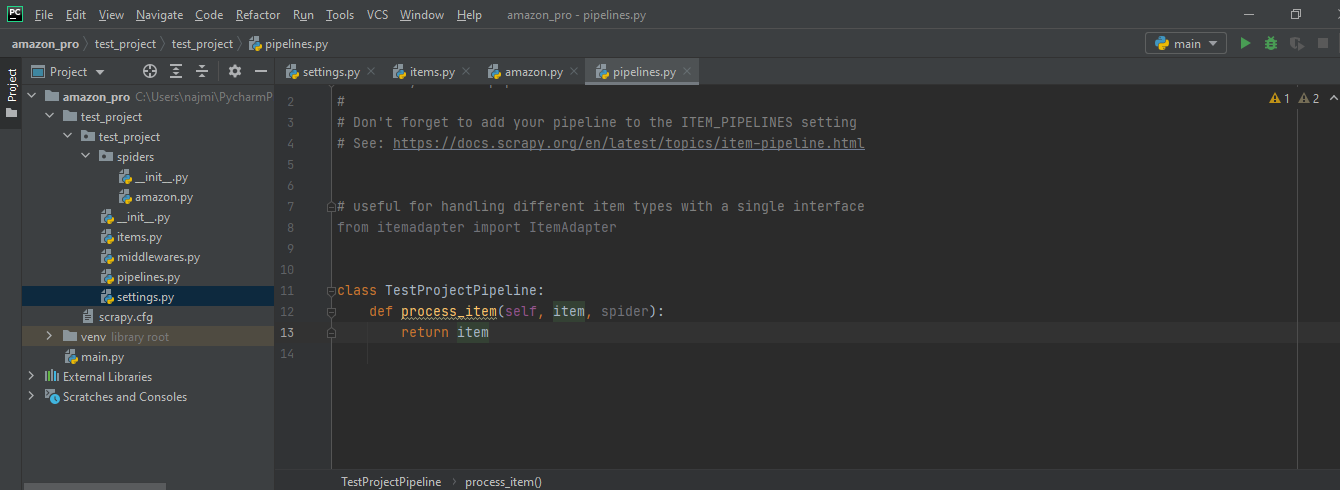
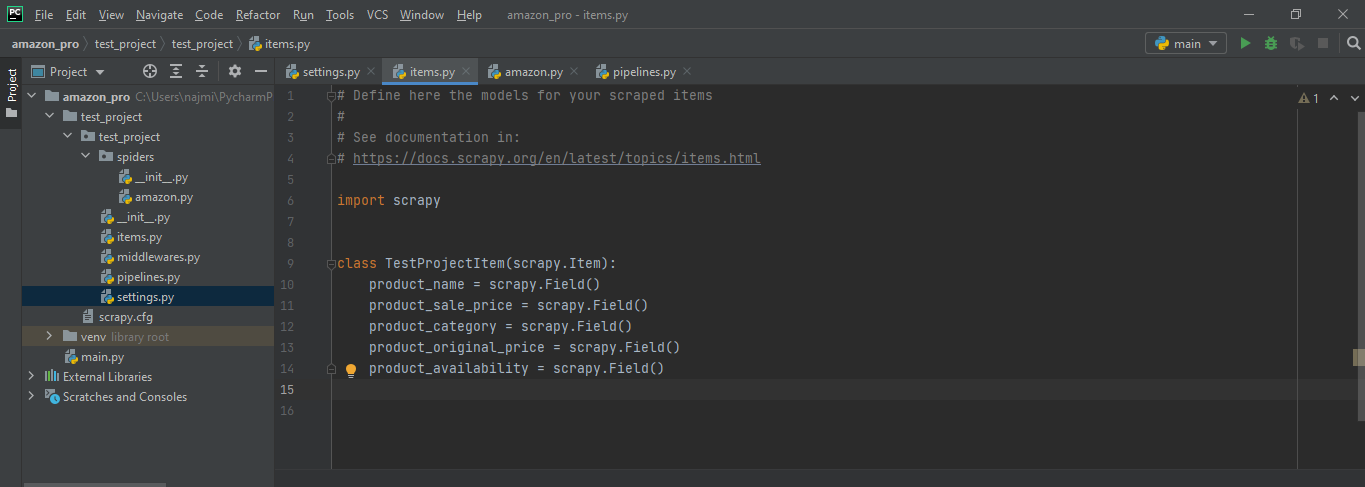
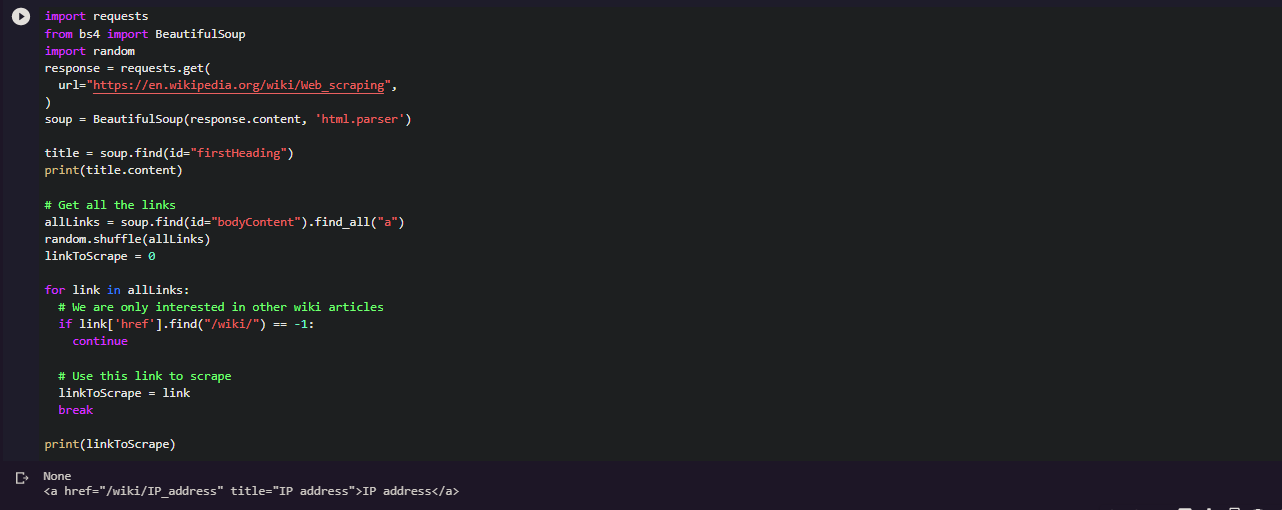
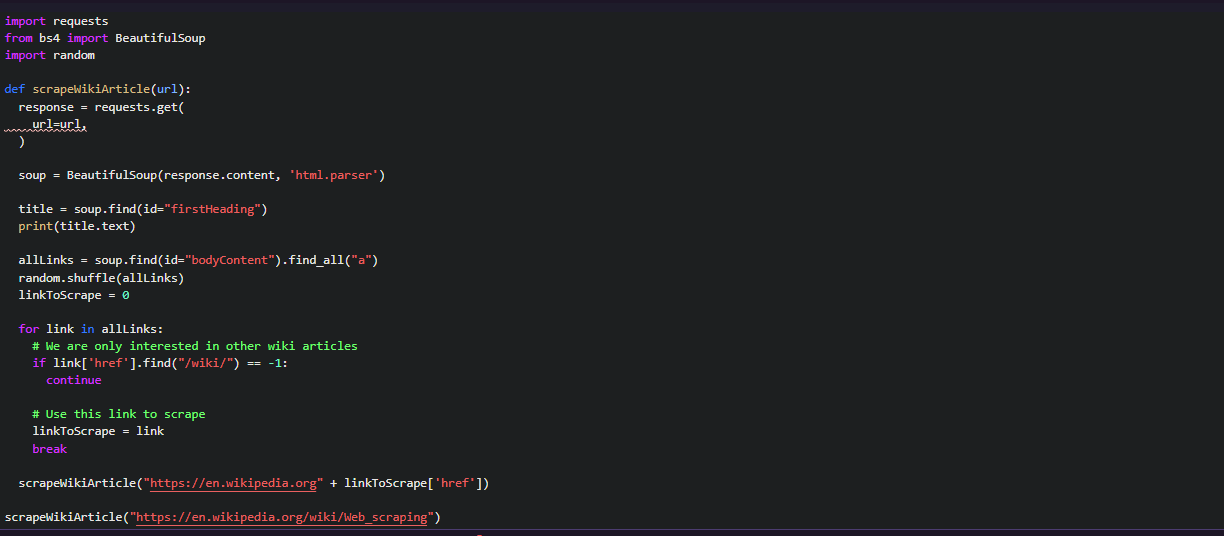
We have compiled most frequently asked Python Interview Questions which will help you with different expertise levels.
Python Interview Questions on Array Sequence
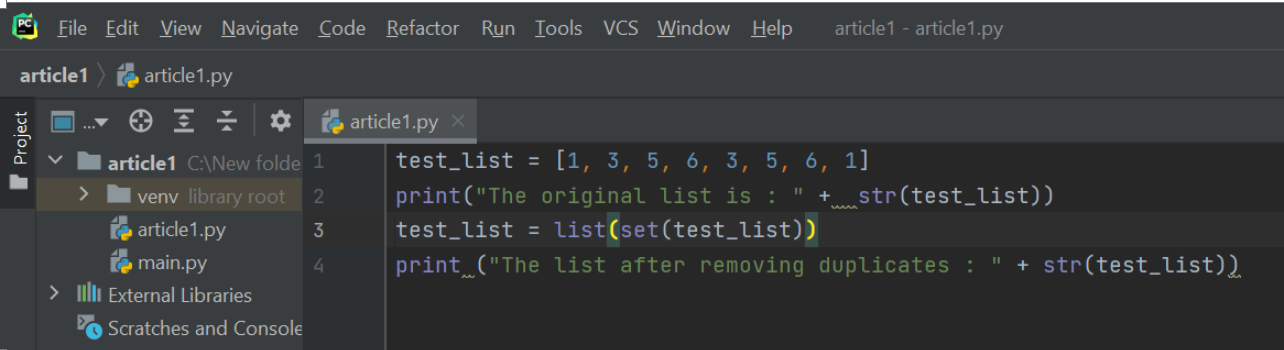
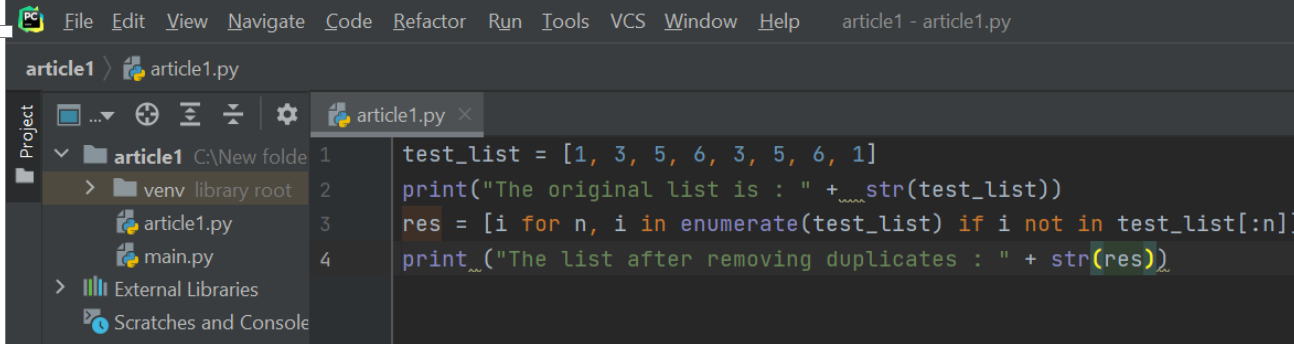
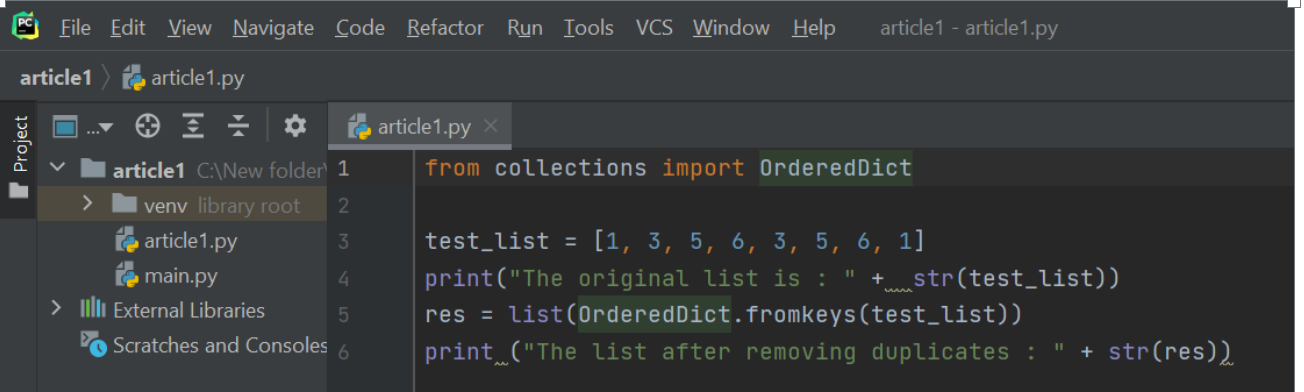
Low Level Arrays
Let’s try to understand how information is stored in low-level computer architecture in order to understand how array sequences work. Here is a small brush-up on computer science basics on memory units.
We know that the smallest unit of data in a computer is a bit (0 or 1). 8 bits together make a byte. A byte has 8 binary digits. Characters such as alphabets, numbers, or symbols are stored in bytes. A computer system memory has a huge number of bytes and tracking of how information is stored in these bytes is done with the help of a memory address. Every byte has a unique memory address which makes tracking information easier.
The following diagram depicts a lower-level computer memory. It shows a small section of memory of individual bytes with consecutive addresses.
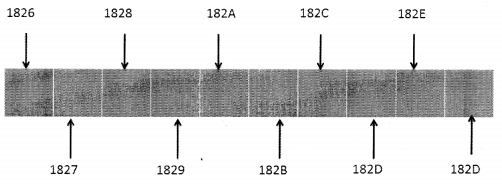
Computer system hardware is designed in such a manner that the main memory can easily access any byte in the system. The primary memory is located in the CPU itself and is known as RAM. Any byte irrespective of the address can be accessed easily. Every byte in memory can be stored or retrieved in constant time, hence its Big-O notation for the time complexity would be O(1).
There is a link between an identifier of a value and the memory address where it is stored, the programming language keeps a track of this association. So, a variable student_name may store name details for a student and class_ teacher would store the name of a class teacher. While programming, it is often required to keep a track of all related objects.
So, if you want to keep a track of scores in various subjects for a student, then it is a wise idea to group these values under one single name, assign each value an index and use the index to retrieve the desired value. This can be done with the help of Arrays. An array is nothing but a contiguous block of memory.
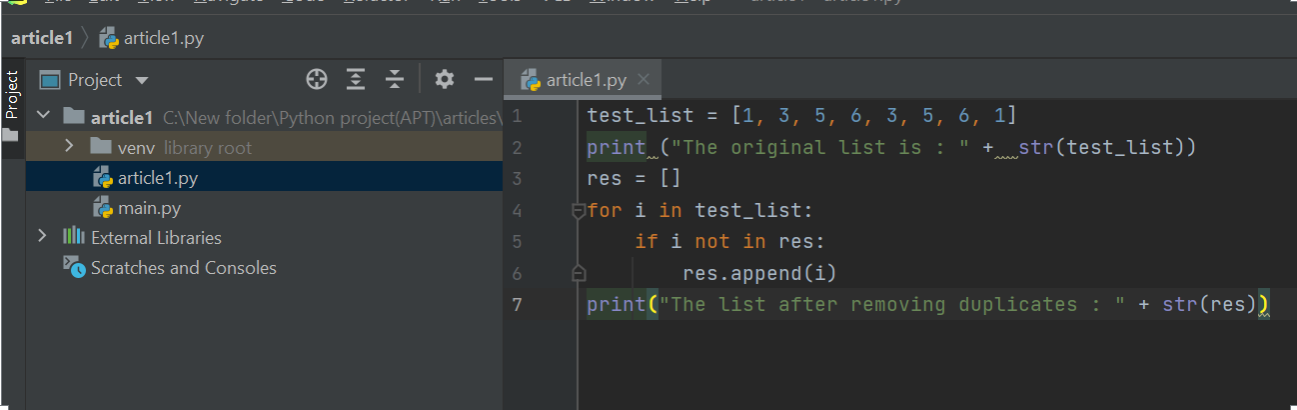
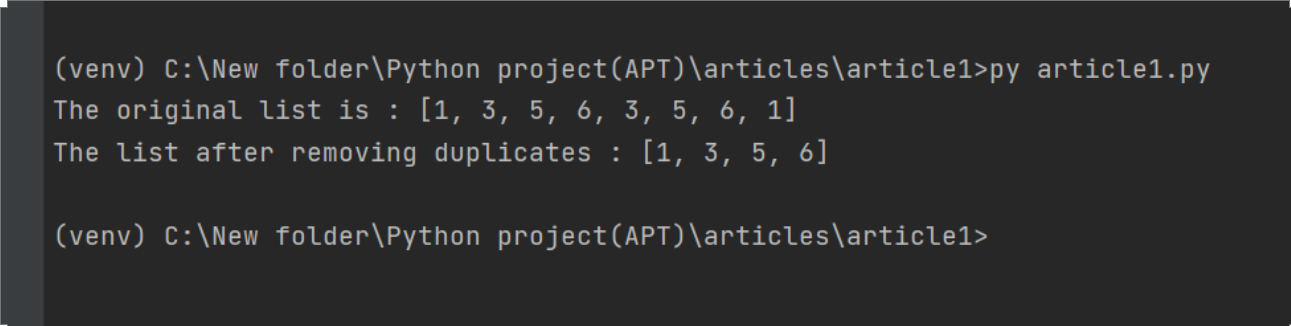
Python internally stores every Unicode character in 2 bytes. So, if you want to store a 5-letter word (let’s say ‘state’) in python, this is how it would get stored in memory:
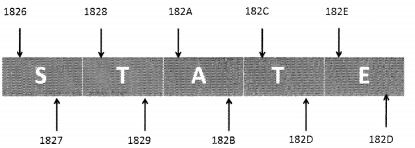
Since each Unicode character occupies 2 bytes, the word STATE is stored in 10 consecutive bytes in the memory. So, this is a case of an array of 5 characters. Every location of an array is referred to as a cell. Every array element is numbered and its position is called index. In other words, the index describes the location of an element.
Table
Every cell of an array must utilize the same number of bytes.
The actual address of the 1st element of the array is called the Base Address. Let’s say the name of the array mentioned above is my_array[ ]. The Base address of my_array[ ] is 1826. If we have this information it is easy to calculate the address of any element in the array.
Address of my array [index] = Base Address +( Storage size in bytes of one element in the array) * index.
Therefore, Address of my array[3] = 1826 + 2*3
= 1826 + 6
= 182C
After that, slight information on how things work at a lower level lets’s get back to the higher level of programming where the programmer is only concerned with the elements and index of the array.
Referential Array
We know that in an array, every cell must occupy the same number of bytes. Suppose we have to save string values for the food menu. The names can be of different lengths. In this case, we can try to save enough space considering the longest possible name that we can think of but that does not seem to be a wise thing to do like a lot of space is wasted in the process and you never know there may be a name longer than the value that we have catered for. A smarter solution, in this case, would be to use an array of object references.
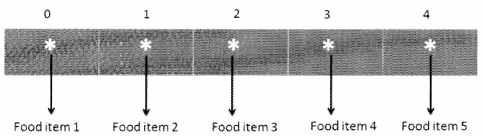
In this case, every element of the array is actually a reference to an object. The benefit of this is that every object which is of string value can be of different length but the addresses will occupy the same number of cells. This helps in maintaining the constant time factor of order O(1).
In Python, lists are referential in nature. They store pointers to addresses in the memory. Every memory address requires a space of 64-bits which is fixed.
Question 1.
You have a list integer list having integer values. What happens when you give the following command?
integer_list[1] + = 7
Answer:
In this case, the value of the integer at index 1 does not change rather we end up referring to space in the memory that stores the new value i.e. the sum of integer_list[1]+7.
Question 2.
State whether True or False:
A single list instance may include multiple references to the same object as elements of the list.
Answer:
True
Question 3.
Can a single object be an element of two or more lists?
Answer:
Yes
Question 4.
What happens when you compute a slice of the list?
Answer:
When you compute a slice of the list, a new list instance is created. This new list actually contains references to the same elements that were in the parent list.
For example:
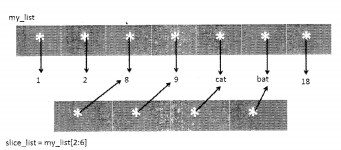
>>> my_list = [1, 2,8,9, "cat", "bat", 18]
>>> slice_list = my_list[2:6]
>>> slice_list
[8, 9, 'cat' , 'bat' ]
>>>
This is shown in the following diagram:
Question 5.
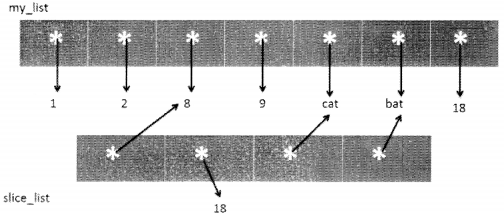
Suppose we change the value of the element at index 1 of the slice just to 18 (preceding diagram). How will you represent this in a diagram?
Answer:
When we say sliceJist[1]=18, we actually are changing the reference that earlier pointed to 9 to another reference that points to value 18. The actual integer object is not changed, only the reference is shifted from one location to the other.
Deep Copy and Shallow Copy in Python
Python has a module named “copy” that allows deep copy or shallow copy mutable objects.
Assignment statements can be used to create a binding between a target and an object, however, they cannot be used for copying purposes.
Deep Copy
The copy module of python defines a deepcopy( ) function which allows the object to be copied into another object. Any changes made to the new object will not be reflected in the original object.
In the case of shallow copy, a reference of the object is copied into another object as a result of which changes made in the copy will be reflected in the parent copy. This is shown in the following code:
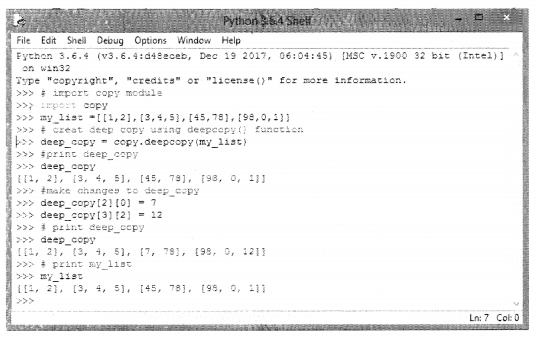
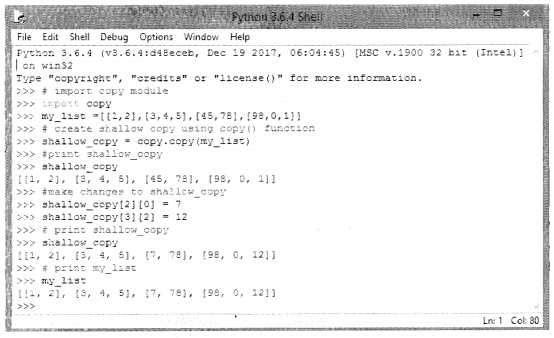
It is important to note here that shallow and deep copying functions should be used when dealing with objects that contain other objects (lists or class instances), A shallow copy will create a compound object and insert into it, the references the way they exist in the original object. A deep copy on the other hand creates a new compound and recursively inserts copies of the objects the way they exist in the original list.
Question 6.
What would be the result of the following statement? my list = [7]* 10?
Answer:
It would create a list named my list as follows:
[7, 7, 7, 7, 7, 7, 7, 7, 7, 7]
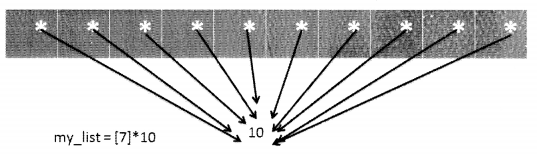
All the 10 cells of the list my_list, refers to the same element which in this case is 10.
Question 7.
Have a look at the following piece of code:
>>> a = [1,2,3,4,5,6,7]
>>> b = a
>>>b [ 0 ] = 8
>>> b
[8, 2, 3, 4, 5, 6, 7]
>>> a
[8, 2, 3, 4, 5, 6, 7]
>>>
Here, we have used the assignment operator still on making changes to ‘b’ changes are reflected in ‘a’. Why?
Answer:
When you use an assignment operator you are just establishing a relationship between an object and the target. You are merely setting a reference to the variable. There are two solutions to this:
(I)
>>> a
[8,2,3, 4, 5, 6, 7]
>>>a = [ 1,2 3, 4,5 ,6, 7]
>>> b = a [:]
>>>b[0] = 9
>>> b
[9, 2, 3, 4, 5, 6, 7]
>>> a
[1, 2, 3, 4, 5, 6, 7]
>>>
(II)
>>> a = [ 1,2 3, 4,5 6, 7]
>>> b = list (a)
>>>b
[1,2, 3, 4, 5, 6, 7]
>>>b [0] = 9
>>> b
[9, 2, 3, 4, 5, 6, 7]
>>> a
[1, 2, 3, 4, 5, 6, 7]
>>>
Question 8.
Take a look at the following piece of code:
>>> import copy
>>> a = [1 9 9 4 5, 5]
>>> b = copy.copy(a)
>>> b
[l, 2, 3, 4, 5, 6]
>>>b [2] = 9
>>> b
[1.2, 9, 4, 5, 6]
>>> a
[1.2, 3, 4, 5, 6]
>>>
‘b’ is a shallow copy of ‘a’ however when we make changes to ‘b’ it is not reflected in ‘a’, why? How can this be resolved?
Answer:
List ‘a’ is a mutable object (list) that consists of immutable objects (integer).
A shallow copy would work with the list containing mutable objects.
You can use b=a to get the desired result.
Question 9.
Look at the following code:
>>> my_list = [["apples", "banana"], ["Rose", "Lotus"], ["Rice", "Wheat"]]
>>> copy_list = list (my_list)
>>> copy_list[2][0]="cereals"
What would happen to the content of my_list? Does it change or remains the same?
Answer:
Content of my_list will change:
>>> my list [['apples', 'banana'] , [ 'Rose', 'Lotus'],
['cereals', 'Wheat']]
>>>
Question 10.
Look at the following code:
>>> my_list = [ ["apples", "banana"], ["Rose", "Lotus"], ["Rice", "Wheat"]]
>>> copy_list = my_list.copy( )
>>> copy_list[2][0]="cereals"
What would happen to the content of my_list? Does it change or remains the same?
Answer:
Content of my_list would change:
>>> my_list
[ [ 'apples' , 'banana1' ] , [ 'Rose' , 'Lotus' ] ,
[ 'cereals', 'Wheat']]
>>>
Question 11.
When the base address of immutable objects is copied it is called_________________.
Answer:
Shallow copy
Question 12.
What happens when a nested list undergoes deep copy?
Answer:
When we create a deep copy of an object, copies of nested objects in the original object are recursively added to the new object. Thus, a deep copy will create a completely independent copy of not only of the object but also of its nested objects.
Question 13.
What happens when a nested list undergoes shallow copy?
Answer:
A shallow copy just copies references of nested objects therefore the copies of objects are not created.
Dynamic Arrays
As the name suggests dynamic array is a contiguous block of memory that grows dynamically when new data is inserted. It has the ability to adjust its size automatically as and when there is a requirement, as a result of which, we need not specify the size of the array at the time of allocation and later we can use it to store as many elements as we want.
When a new element is inserted in the array, if there is space then the element is added at the end else a new array is created that is double in size of the current array, so elements are moved from the old array to the new array and the old array is deleted in order to create some free memory space. The new element is then added at the end of the expanded array.
Let’s try to execute a small piece of code. This example is executed on 32-bit machine architecture. The result can be different from that of 64-bit but the logic remains the same.
For a 32-bit system 32-bits (i.e 4 bytes) are used to hold a memory address. So, now let’s try and understand how this works:
When we created a blank list structure, it occupies 36 bytes in size. Look at the code given as follows:
import sys
my_dynamic_list =[ ]
print("length = ",len(my_dynamic_list) , ".", "size in bytes = ", sys.getsizeof(my_dynamic_list),".")Here we have imported the sys module so that we can make use of getsizeof( ) function to find the size, the list occupies in the memory.
The output is as follows:
Length = 0.
Size in bytes = 36 .
Now, suppose we have a list of only one element, let’s see how much size it occupies in the memory.
import sys
my_dynamic_list =[1]
print("length = ",len(my_dynamic_list),".", "size in bytes = ", sys.getsizeof(my_dynamic_list),".")
length = 1 . size in bytes = 40 .This 36 byte is just the requirement of the list data structure on 32- bit architecture.
If the list has one element that means it contains one reference to memory and in a 32-bit system architecture memory, the address occupies 4 bytes. Therefore, the size of the list with one element is 36+4 = 40 bytes.
Now, let’s see what happens when we append to an empty list.
import sys
my_dynamic_list =[ ]
value = 0
for i in range(20):
print("i = ",i,".", " Length of my_
dynamic_list = ",len(my_dynamic_list),".", " size in bytes = ", sys.getsizeof(my_dynamic_ list),".")
my_dynamic_list.append(value)
value +=1Output
i = 0 . Length of mydynamic list = 0 . size in bytes =36
i = 1 . Length of my_dynamic_list = 1 . size in bytes = 52
i = 2 . Length of my_dynamic list = 2 . size in bytes = 52
i = 3 . Length of my dynamic list = 3 . size in bytes = 52
i = 4. Length of my dynamic list = 4 . size in bytes = 52
i= 5. Length of my dynamic list = 5 . size in bytes = 68
i = 6. Length of my_dynamic_list = 6 . size in bytes = 68
i = 7. Length of my_dynamic_list = 7 . size in bytes = 68
i = 8 . Length of my_dynamic_list = 8 . size in bytes = 68
i = 9. Length of my_dynamic_list = 9 . size in bytes = 100
i = 10. Length of my dynamic list =10. size in bytes = 100
i = 11 . Length of my dynamic list =11. size in bytes = 100
i = 12 . Length of my_dynamic_list = 12 . size in bytes = 100
i = 13 . Length of my dynamic list =13. size in bytes = 100
i = 14. Length of my_dynamic_list = 14 . size in bytes = 100
i = 15 . Length of my dynamic list =15. size in bytes = 100
i = 16. Length of my dynamic list = 16. size in bytes = 100
i = 17. Length of my_dynamic_list =17. size in bytes = 136
i = 18 . Length of my dynamic list =18. size in bytes = 136
i = 19. Length of my_dynamic_list = 19. size in bytes = 136
Now, lets have a look at how things worked here:
When you call an append( ) function for list, resizing takes place as per list_resize( ) function defined in Objects/listobject.c file in Python. The job of this function is to allocate cells proportional to the list size thereby making space for additional growth.
The growth pattern is : 0,4,8,16,25,35,46,58,72,88,
Amortization
Let’s suppose that there is a man called Andrew, who wants to start his own car repair shop and has a small garage. His business starts and he gets his first customer however, the garage has space only to keep one car. So, he can only have one car in his garage.

Seeing a car in his garage, another person wants to give his car to him. Andrew, for the ease of his business, wants to keep all cars in one place. So, in order to keep two cars, he must look for space to keep two cars, move the old car to the new space and also move the new car to the new space and see how it works.
So, basically, he has to:
- Buy new space
- Sell the old space
Let’s say, this process takes one unit of time. Now, he also has to:
- Move the old car to a new location
- Move the new car to a new location Moving each car takes one unit of time.
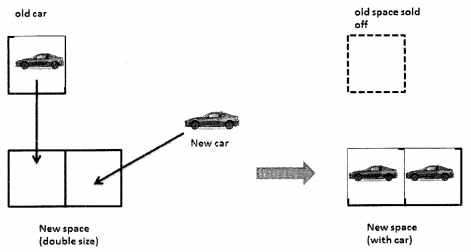
Andrew is new in the business. He does not know how his business would expand, also what is the right size for the garage. So, he comes up with the idea that if there is space in his garage then he would simply add the new car to space, and when the space is full he will get a new space twice as big as the present one and then move all cars there and get rid of old space. So, the moment he gets his new car, it’s time to buy a new space twice the old space and get rid of the old space.
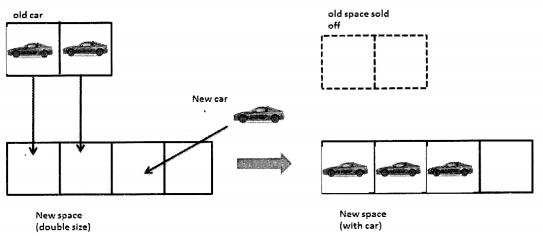
Now, when the fourth car arrives Andrew need not worry. He has space for the car.
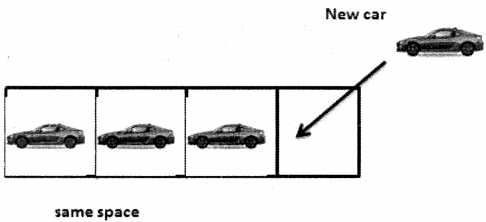
And now again when he gets the fifth car he will have to buy a space that is double the size of the space that he currently has and sell the old space.
So, let’s now take a look at the time complexity: Let’s analyze how much does it take to add a car to Andrew’s garage where there is n number of cars in the garage.
Here is what we have to see:
1. If there is space available, Andrew just has to move one car into a new space and that takes only one unit of time. This action is independent of the n (number of cars in the garage). Moving a car in a garage that has space is constant time i.e. O(1).
2. When there in spot and a new car arrives, Andrew has to do the following:
- Buy a new space that takes 1 unit of time.
- Move all cars into new space one by one and then move the new car into free space. Moving every car takes one unit of time.
So, if there were n cars already in the old garage, plus one car then that would take n+1 time units to move the car.
So, the total time taken in step two is 1+n+l and in Big O notation this would mean O(n) as the constant does not matter.
On the look of it, one may think this is too much of a task but every business plan should be correctly analyzed. Andrew will buy a new garage only if the space that he has, gets all filled up. On spreading out the cost over a period of time, one will realize that it takes a good amount of time only when the space is full but in a scenario where there is space, the addition of cars does not take much time.
Now keeping this example in mind we try to understand the amortization of dynamic arrays. We have already learned that in a dynamic array when the array is full and a new value has to be added, the contents of the array are moved on to the new array that is double in size, and then the space occupied by the old array is released.
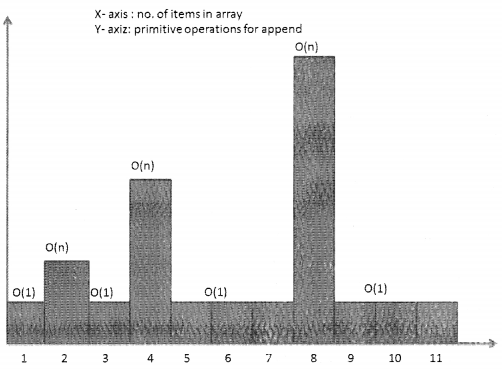
It may seem like the task of replacing the old array with a new one is likely to slow down the system. When the array is full, appending a new element may require O(n) time. However, once the new array has been created we can add new elements to the array in constant time O(1) till it has to be replaced again. We will now see that with the help of amortization analysis how this strategy is actually quite efficient.
As per the graph above, when there are two elements then on calling append, the array will have to double in size, same after 4th and 8th element. So, at 2, 4, 8, 16… append will be O(n) and for the rest of the cases, it will be 0(1).
The steps involved are as follows:
- When the array is full, allocate memory for the new array and the size of the new array should typically be twice the size of the old array.
- All contents from the old array should be copied to the new array.
- The space occupied by the old array should be released.
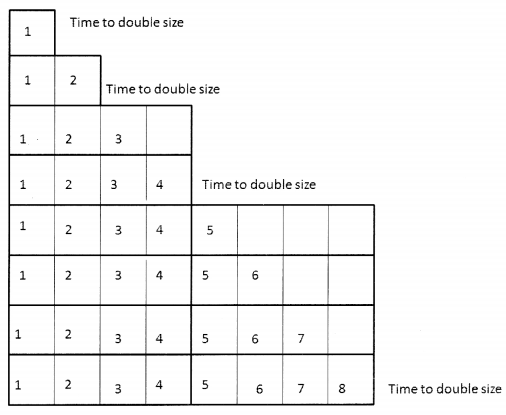
The analysis would be as follows: