Python Data Persistence – Python – SQLAIchemy
The concluding paragraph of the previous chapter briefly talked about the disparity between type systems of SQL and object-oriented programming languages such as Python. Apart from Python’s Number (that too int and float only, not complex) and string types (which are generally called scalar types), SQL doesn’t have an equivalent data type for others such as diet, tuple, list, or any user-defined class.
If you have to store such an object in a relational database, it must be deconstructed into SQL data types first, before performing INSERT operation. On the other hand, a Python object of the desired type will have to be constructed by using data retrieved from a SQL table, before a Python script is able to process it.
Let’s take the case of ‘Products’ table in the SQLite database used in the previous chapter. Its structure is as follows:
Example
CREATE TABLE Products (
ProductID INTEGER PRIMARY KEY AUTOINCREMENT,
Name TEXT (20),
Price INTEGER
) ;
On the other side, Python script has a Products class and its object is populated with data as below:
Example
class Product
def __init__(self, id, name, price):
self.id=id
self.name=name
self.price=price
p1=Product(1, Laptop 1,25000)
Following sqlite3 module syntax, the following statement will insert pi object in the Products table:
Example
cur.execute("insert into products values
(?,?,?);",(self.id, self.name, self.price))Similarly, following statements will store retrieved data in an object of Products class.
Example
cur.execute('select * from products where name=?',
(1 Laptop',)) row=cur.fetchone()
p1=Products(row[0], row[1],row[2])As you can see, this involves a tedious and explicit packing and unpacking of Python objects in order to be compatible with SQL data types. This is where Object Relational Mappers are useful.
WhatisORM?
An Object Relation Mapper (ORM) library provides a seamless interface between a class and a SQL table. A class is mapped to a certain table in the database, so that cumbersome to and fro conversion between object and SQL types are automated. The products class in Python code can be mapped to the Products table in the database. As a result, all CRUD operations are done with the help of objects only, not requiring hard-coded SQL queries to be used in Python script.
ORMs thus provides an abstraction layer over the raw SQL queries, thus enabling rapid application development. Such ORM libraries are available for most programming languages including Python. SQLAlchemy is a popular database toolkit widely used by Python developers. SQL ALchemy’s ORM system transparently synchronizes all changes in the state of an object of a user-defined class with its related row in the database table.
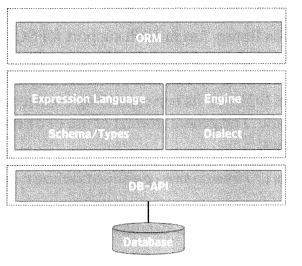
SQLAlchemy interacts with a certain type of database in association with the respective DB-API compliant module. Its dialect system is able to establish interaction with a database through the latter’s DB-API driver. That means you should have a corresponding DB-API module also installed along with SQLAlchemy to be able to use a particular type of RDBMS.
As a matter of fact, SQLALchemy library also contains, in addition to ORM API, the SQL Expression Language (SQLAlchemy Core) that executes primitive constructs of the relational database directly. While our focus in this chapter is on SQLALChemy ORM, we shall also briefly SQL Expression language in the end. (figure 9.1)
In most cases, SQLAlchemy is installed with the help of a pip utility. As explained in —, a virtual environment with SQLAlchemy installed will be used for this chapter. We need to activate it and start a Python interpreter.
Example
E:\SQLAlchemyEnv>scripts\activate
(SQLAlchemyEnv) E:\SQLAlchemyEnv>python
Python 3.7.2 (tags/v3.7.2:9a3ffc0492, Dec 23 2018, 23:09:28)
[MSC v.1916 64 bit (AMD64)] on Win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
ORM – Session object
Now that we have created the Products table in the database, the next step is to start the transaction session. A session object is a handle used to interact with the database. We define a Session class that will serve as a factory for new Session objects with the help of the session maker () function.
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
Here the engine is the Engine object that represents a connection with our database. Whenever you need to have a conversation with the database, you instantiate a Session:
session = Session ( )
The session remains in force till changes to the database are committed and/or the close () method is called on a session object.